PaddleNLP预训练模型适用任务汇总(点击展开详情)
| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
-| :----------------- | ----------------------- | -------------------- | ------------------ | --------------- | --------------- |
+|:-------------------|-------------------------|----------------------|--------------------|-----------------|-----------------|
| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
@@ -233,7 +233,7 @@ model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
### 产业级端到端系统范例
-PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高频NLP场景,提供了端到端系统范例,打通*数据标注*-*模型训练*-*模型调优*-*预测部署*全流程,持续降低NLP技术产业落地门槛。更多详细的系统级产业范例使用说明请参考[Applications](./applications)。
+PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高频NLP场景,提供了端到端系统范例,打通*数据标注*-*模型训练*-*模型调优*-*预测部署*全流程,持续降低NLP技术产业落地门槛。更多详细的系统级产业范例使用说明请参考[Applications](./legacy/applications)。
#### 🔍 语义检索系统
@@ -244,7 +244,7 @@ PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高
-更多使用说明请参考[语义检索系统](./applications/neural_search)。
+更多使用说明请参考[语义检索系统](./legacy/applications/neural_search)。
#### ❓ 智能问答系统
@@ -255,7 +255,7 @@ PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高
-更多使用说明请参考[智能问答系统](./applications/question_answering)与[文档智能问答](./applications/document_intelligence/doc_vqa)
+更多使用说明请参考[智能问答系统](./legacy/applications/question_answering)与[文档智能问答](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/document_intelligence/doc_vqa)
#### 💌 评论观点抽取与情感分析
@@ -265,36 +265,20 @@ PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高
 -更多使用说明请参考[情感分析](./applications/sentiment_analysis)。
+更多使用说明请参考[情感分析](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/sentiment_analysis)。
#### 🎙️ 智能语音指令解析
-集成了[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)和[百度开放平台](https://ai.baidu.com/)的语音识别和[UIE](./model_zoo/uie)通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。
+集成了[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)和[百度开放平台](https://ai.baidu.com/)的语音识别和[UIE](./legacy/model_zoo/uie)通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。
-更多使用说明请参考[情感分析](./applications/sentiment_analysis)。
+更多使用说明请参考[情感分析](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/sentiment_analysis)。
#### 🎙️ 智能语音指令解析
-集成了[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)和[百度开放平台](https://ai.baidu.com/)的语音识别和[UIE](./model_zoo/uie)通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。
+集成了[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)和[百度开放平台](https://ai.baidu.com/)的语音识别和[UIE](./legacy/model_zoo/uie)通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。

-  -
-
-
-```python
-model = GPTLMHeadModel.from_pretrained('gpt-cpm-large-cn')
-...
-outputs, _ = model.generate(
- input_ids=inputs_ids, max_length=10, decode_strategy='greedy_search',
- use_fast=True)
-```
-
-简单地在`generate()`API上打开`use_fast=True`选项,轻松在Transformer、GPT、BART、PLATO、UniLM等生成式预训练模型上获得5倍以上GPU加速,更多使用说明可参考[FastGeneration文档](./fast_generation)。
-
#### 🚀 Fleet:飞桨4D混合并行分布式训练技术
-
@@ -302,7 +286,7 @@ outputs, _ = model.generate(
-更多关于千亿级AI模型的分布式训练使用说明可参考[GPT-3](./examples/language_model/gpt-3)。
+更多关于千亿级AI模型的分布式训练使用说明可参考[GPT-3](./legacy/model_zoo/gpt-3)。
## 社区交流
diff --git a/README_en.md b/README_en.md
index 4801677d17be..de33396f3dea 100644
--- a/README_en.md
+++ b/README_en.md
@@ -25,8 +25,7 @@
* **2024.01.04 [PaddleNLP v2.7](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.7.0)**: The LLM experience is fully upgraded, and the tool chain LLM entrance is unified. Unify the implementation code of pre-training, fine-tuning, compression, inference and deployment to the `PaddleNLP/llm` directory. The new [LLM Toolchain Documentation](https://paddlenlp.readthedocs.io/zh/latest/llm/finetune.html) provides one-stop guidance for users from getting started with LLM to business deployment and launch. The full breakpoint storage mechanism Unified Checkpoint greatly improves the versatility of LLM storage. Efficient fine-tuning upgrade supports the simultaneous use of efficient fine-tuning + LoRA, and supports QLoRA and other algorithms.
-* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: Release [Full-process LLM toolchain](./llm) , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in [4D parallel distributed Trainer](./docs/trainer.md ), [Efficient fine-tuning algorithm LoRA/Prefix Tuning](./llm#33-lora), [Self-developed INT8/INT4 quantization algorithm](./llm#6-quantization), etc.; fully supports [LLaMA 1/2](./llm/llama), [BLOOM](.llm/bloom), [ChatGLM 1/2](./llm/chatglm), [GLM](./llm/glm), [OPT](./llm/opt) and other mainstream LLMs.
-
+* **2023.08.15 [PaddleNLP v2.6](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.6.0)**: Release [Full-process LLM toolchain](./llm) , covering all aspects of pre-training, fine-tuning, compression, inference and deployment, providing users with end-to-end LLM solutions and one-stop development experience; built-in [4D parallel distributed Trainer](./docs/trainer.md ), [Efficient fine-tuning algorithm LoRA/Prefix Tuning](./llm/README.md#2-%E7%B2%BE%E8%B0%83), [Self-developed INT8/INT4 quantization algorithm](./llm/README.md#4-%E9%87%8F%E5%8C%96), etc.; fully supports [LLaMA 1/2](./llm/config/llama), [BLOOM](./llm/config/bloom), [ChatGLM 1/2](./llm/config/chatglm), [OPT](./llm/config/opt) and other mainstream LLMs.
## Installation
@@ -119,7 +118,7 @@ model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
#### Wide-range NLP Task Support
-PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer [Model Zoo](./model_zoo), and wide-range NLP application [examples](./examples) with detailed instructions.
+PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer [Model Zoo](./legacy/model_zoo), and wide-range NLP application [examples](./legacy/examples) with detailed instructions.
Also you can run our interactive [Notebook tutorial](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995) on AI Studio, a powerful platform with **FREE** computing resource.
@@ -176,7 +175,7 @@ For more pretrained model usage, please refer to [Transformer API Docs](./docs/m
We provide high value scenarios including information extraction, semantic retrieval, question answering high-value.
-For more details industrial cases please refer to [Applications](./applications).
+For more details industrial cases please refer to [Applications](./legacy/applications).
#### 🔍 Neural Search System
@@ -186,7 +185,7 @@ For more details industrial cases please refer to [Applications](./applications)
-For more details please refer to [Neural Search](./applications/neural_search).
+For more details please refer to [Neural Search](./legacy/applications/neural_search).
#### ❓ Question Answering System
@@ -197,7 +196,7 @@ We provide question answering pipeline which can support FAQ system, Document-le
-For more details please refer to [Question Answering](./applications/question_answering) and [Document VQA](./applications/document_intelligence/doc_vqa).
+For more details please refer to [Question Answering](./legacy/applications/question_answering) and [Document VQA](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/document_intelligence/doc_vqa).
#### 💌 Opinion Extraction and Sentiment Analysis
@@ -209,7 +208,7 @@ We build an opinion extraction system for product review and fine-grained sentim
-For more details please refer to [Sentiment Analysis](./applications/sentiment_analysis).
+For more details please refer to [Sentiment Analysis](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/sentiment_analysis).
#### 🎙️ Speech Command Analysis
@@ -220,26 +219,10 @@ Integrated ASR Model, Information Extraction, we provide a speech command analys
-For more details please refer to [Speech Command Analysis](./applications/speech_cmd_analysis).
+For more details please refer to [Speech Command Analysis](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/speech_cmd_analysis).
### High Performance Distributed Training and Inference
-#### ⚡ FastGeneration: High Performance Generation Library
-
-
-
-
-
-```python
-model = GPTLMHeadModel.from_pretrained('gpt-cpm-large-cn')
-...
-outputs, _ = model.generate(
- input_ids=inputs_ids, max_length=10, decode_strategy='greedy_search',
- use_fast=True)
-```
-
-Set `use_fast=True` to achieve 5x speedup for Transformer, GPT, BART, PLATO, UniLM text generation. For more usage please refer to [FastGeneration](./fast_generation).
-
#### 🚀 Fleet: 4D Hybrid Distributed Training
-
@@ -247,7 +230,7 @@ Set `use_fast=True` to achieve 5x speedup for Transformer, GPT, BART, PLATO, Uni
-For more super large-scale model pre-training details please refer to [GPT-3](./examples/language_model/gpt-3).
+For more super large-scale model pre-training details please refer to [GPT-3](./legacy/model_zoo/gpt-3).
## Quick Start
diff --git a/docs/FAQ.md b/docs/FAQ.md
index db2b4ac52fc6..8b4dd5f0efa9 100644
--- a/docs/FAQ.md
+++ b/docs/FAQ.md
@@ -132,7 +132,7 @@ emb.set_state_dict(load_layer_state_dict) # 加载模型参数
##### Q1.4 当训练样本较少时,有什么推荐的方法能提升模型效果吗?
-**A:** 增加训练样本带来的效果是最直接的。此外,可以基于我们开源的[预训练模型](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers)进行热启,再用少量数据集fine-tune模型。此外,针对分类、匹配等场景,[小样本学习](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/few_shot)也能够带来不错的效果。
+**A:** 增加训练样本带来的效果是最直接的。此外,可以基于我们开源的[预训练模型](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers)进行热启,再用少量数据集fine-tune模型。此外,针对分类、匹配等场景,[小样本学习](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/few_shot)也能够带来不错的效果。
@@ -140,7 +140,7 @@ emb.set_state_dict(load_layer_state_dict) # 加载模型参数
**A:** 从工程角度,对于服务器端部署可以使用[Paddle Inference](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/inference_cn.html)高性能预测引擎进行预测部署。对于Transformer类模型的GPU预测还可以使用PaddleNLP中提供的[FastGeneration](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/ops)功能来进行快速预测,其集成了[NV FasterTransformer](https://github.com/NVIDIA/FasterTransformer)并进行了功能增强。
-从模型策略角度,可以使用一些模型小型化技术来进行模型压缩,如模型蒸馏和裁剪,通过小模型来实现加速。PaddleNLP中集成了ERNIE-Tiny这样一些通用小模型供下游任务微调使用。另外PaddleNLP提供了[模型压缩示例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/model_compression),实现了DynaBERT、TinyBERT、MiniLM等方法策略,可以参考对自己的模型进行蒸馏压缩。
+从模型策略角度,可以使用一些模型小型化技术来进行模型压缩,如模型蒸馏和裁剪,通过小模型来实现加速。PaddleNLP中集成了ERNIE-Tiny这样一些通用小模型供下游任务微调使用。另外PaddleNLP提供了[模型压缩示例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/model_compression),实现了DynaBERT、TinyBERT、MiniLM等方法策略,可以参考对自己的模型进行蒸馏压缩。
@@ -181,7 +181,7 @@ emb.set_state_dict(load_layer_state_dict) # 加载模型参数
**A:** 预训练模型通常会有配套的tokenzier和词典,对于大多数中文预训练模型,如ERNIE-3.0,使用的都是字粒度的输入,tokenzier会将句子转换为字粒度的形式,模型无法收到词粒度的输入。如果希望引入额外的词典,需要修改预训练模型的tokenizer和词典,可以参考这里[blog](https://kexue.fm/archives/7758/comment-page-1#Tokenizer ),另外注意embedding矩阵也要加上这些新增词的embedding表示。
-另外还有一种方式可以使用这些字典信息,可以将数据中在词典信息中的词进行整体mask进行一个mask language model的二次预训练,这样经过二次训练的模型就包含了对额外字典的表征。可参考 [PaddleNLP 预训练数据流程](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-1.0/)。
+另外还有一种方式可以使用这些字典信息,可以将数据中在词典信息中的词进行整体mask进行一个mask language model的二次预训练,这样经过二次训练的模型就包含了对额外字典的表征。可参考 [PaddleNLP 预训练数据流程](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/model_zoo/ernie-1.0/)。
此外还有些词粒度及字词混合粒度的预训练模型,在这些词粒度的模型下引入额外的词表也会容易些,我们也将持续丰富PaddleNLP中的预训练模型。
@@ -321,7 +321,7 @@ model.set_state_dict(paddle.load("xxx_para"))
(2)对于第二种方法:
-- 我们在PaddleNLP的examples目录下提供了常见任务的训练与预测脚本:如[GLUE](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/benchmark/glue) 和 [SQuAD](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/machine_reading_comprehension/SQuAD)等
+- 我们在PaddleNLP的examples目录下提供了常见任务的训练与预测脚本:如[GLUE](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/benchmark/glue) 和 [SQuAD](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/machine_reading_comprehension/SQuAD)等
- 开发者可以参考上述脚本进行自定义训练与预测脚本的开发。
@@ -343,7 +343,7 @@ model.set_state_dict(paddle.load("xxx_para"))
(2)如果是下游任务模型,查看是否所有模型参数都被导入了,直接使用bert-base这种预训练模型是不包含任务相关参数的,要确认导入的是微调后的模型,否则任务相关参数会随机初始化导致出现随机性。
-(3)部分算子使用CUDNN后端产生的不一致性可以通过环境变量的设置来避免。如果模型中使用了CNN相关算子,可以设置`FLAGS_cudnn_deterministic=True`。如果模型中使用了RNN相关算子,可以设置`CUBLAS_WORKSPACE_CONFIG=:16:8`或`CUBLAS_WORKSPACE_CONFIG=:4096:2`(CUDNN 10.2以上版本可用,参考[CUDNN 8 release note](https://docs.nvidia.com/deeplearning/sdk/cudnn-release-notes/rel_8.html))。
+(3)部分算子使用CUDNN后端产生的不一致性可以通过环境变量的设置来避免。如果模型中使用了CNN相关算子,可以设置`FLAGS_cudnn_deterministic=True`。如果模型中使用了RNN相关算子,可以设置`CUBLAS_WORKSPACE_CONFIG=:16:8`或`CUBLAS_WORKSPACE_CONFIG=:4096:2`(CUDNN 10.2以上版本可用,参考[CUDNN 8 release note](https://docs.nvidia.com/deeplearning/cudnn/archives/cudnn-894/release-notes/index.html))。
@@ -408,7 +408,7 @@ model.set_state_dict(paddle.load("xxx_para"))
##### Q4.4 【语义匹配】语义索引和语义匹配有什么区别?
-**A:** 语义索引要解决的核心问题是如何从海量 Doc 中通过 ANN 索引的方式快速、准确地找出与 query 相关的文档,语义匹配要解决的核心问题是对 query和文档更精细的语义匹配信息建模。换个角度理解, [语义索引](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/semantic_indexing)是要解决搜索、推荐场景下的召回问题,而[语义匹配](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_matching)是要解决排序问题,两者要解决的问题不同,所采用的方案也会有很大不同,但两者间存在一些共通的技术点,可以互相借鉴。
+**A:** 语义索引要解决的核心问题是如何从海量 Doc 中通过 ANN 索引的方式快速、准确地找出与 query 相关的文档,语义匹配要解决的核心问题是对 query和文档更精细的语义匹配信息建模。换个角度理解, [语义索引](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/semantic_indexing)是要解决搜索、推荐场景下的召回问题,而[语义匹配](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/text_matching)是要解决排序问题,两者要解决的问题不同,所采用的方案也会有很大不同,但两者间存在一些共通的技术点,可以互相借鉴。
diff --git a/docs/advanced_guide/fastgeneration/fastgeneration.rst b/docs/advanced_guide/fastgeneration/fastgeneration.rst
deleted file mode 100644
index 95fff8849aef..000000000000
--- a/docs/advanced_guide/fastgeneration/fastgeneration.rst
+++ /dev/null
@@ -1,189 +0,0 @@
-========
-FastGeneration加速生成API
-========
-
-FastGeneration是PaddleNLP v2.2版本加入的一个高性能推理功能,可实现基于CUDA的序列解码。该功能可以用于多种生成类的预训练NLP模型,例如GPT、BART、UnifiedTransformer等,并且支持多种解码策略。因此该功能主要适用于机器翻译,文本续写,文本摘要,对话生成等任务。
-
-功能底层依托于 `FasterTransformer
+  +
+
+
+
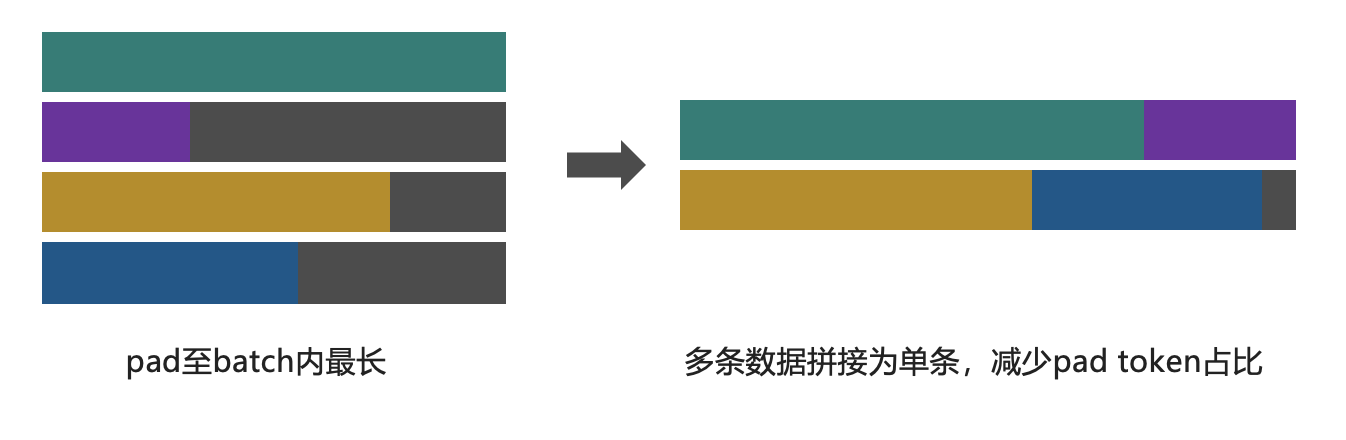
+ Zero Padding策略图示意,能够有效减少无效Pad Token进行训练
+
+
+
+
+
+- **PEFT结合低比特和分布式策略**
+
+PEFT(Parameter-Efficient Fine-Tuning)相比于全量参数大大降低了所需的显存资源,但对于百亿级别的模型对训练资源仍然要求很高。为了减少显存资源占用,PEFT中提供将16位浮点数的主干模型转化为4比特或8比特的量化模型,只有当权重参与计算时才将低比特的主干模型反量化为浮点数模型。PaddleNLP中提供量化为**INT4、INT8、NF4、FP4**等多种低比特数据类型。
+
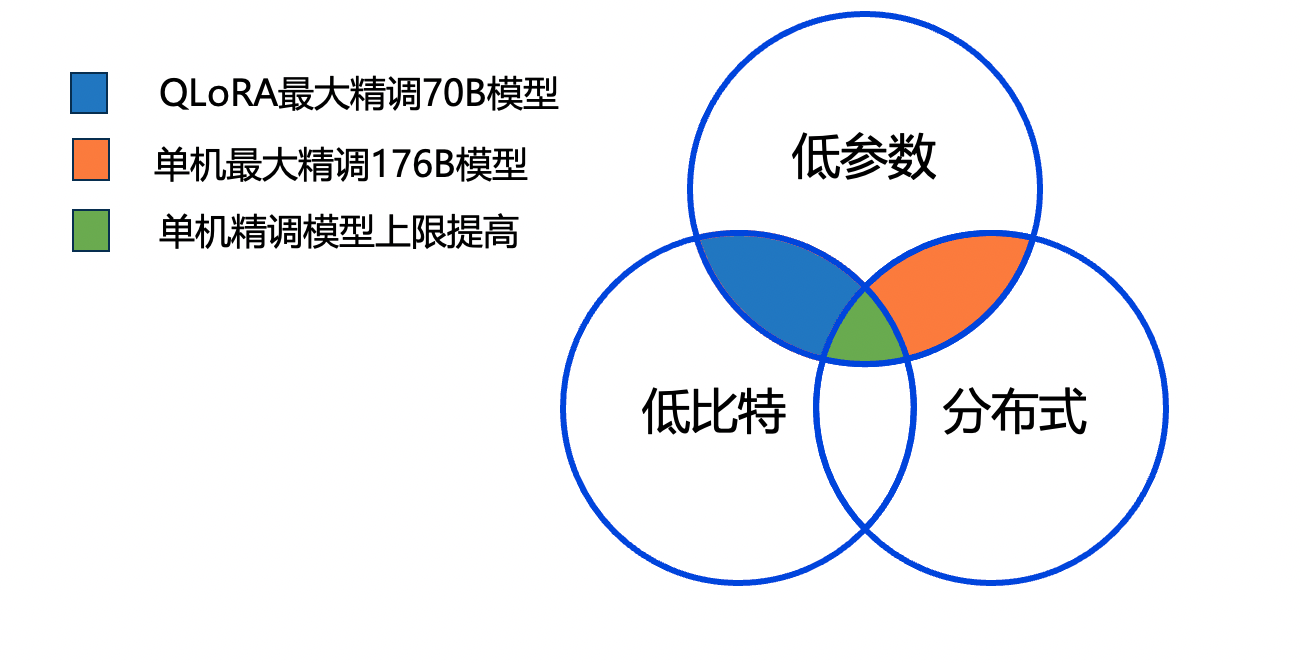
+对于千亿参数级别的模型,PEFT配合低比特策略并不能在单卡训练。PaddleNLP中支持上述所有PEFT策略包含低比特策略使用数据并行(data parallel)、张量并行(tensor parallel)、流水线并行(pipeline parallel)策略、分组参数切分并行
+(Sharding)。PEFT、低比特策略、分布式能力三者组合,PaddleNLP在有限计算资源下,可以将模型微调拓展到单机(80G * 8)**千亿参数级别**。
+
+  +
+
+
+- **统一对话模板**
+
+当前开源Chat 类型模型越来越多,PaddleNLP 已经集成了 [LLaMA/LLaMA2](../config/llama)、[Baichuan/Baichuan2](../config/baichuan)、[ChatGLM](../config/chatglm)、[ChatGLM2/ChatGLM3](../config/chatglm2)、[Qwen](../config/qwen)、[Bloom](../config/bloom)、[GPT-3](../config/gpt-3)等系列模型,也支持[多轮对话 Prompt Template 推理](https://paddlenlp.readthedocs.io/zh/latest/get_started/chat_template.html),只需要调用`apply_chat_template` 函数即可构造将对话历史和用户最新 query 按照模型指定规则拼接到一起,实现不同模型的定制化 Prompt 规则推理。
+
+此外多轮对话训练精调的应用场景也是越来越多,不同模型的多轮对话模板构造规则都不一致,为了在训练侧标准化前处理上的区别,设计了`chat_template`来解决此问题。只需要添加一个`chat_template` 的配置即可为该模型添加相应的多轮对话精调训练支持,具体的配置可看[多轮对话文档](./chat_template.md)。
+
+## 2. 快速开始
+
+接下来我们将以**Llama 2**为例介绍如何使用统一脚本进行SFT、LoRA、Prefix Tuning。
+### 2.1 环境准备
+
+- PaddlePaddle develop
+- PaddleNLP develop
+- PaddleSlim develop
+
+git clone 代码到本地,即可开始。
+
+```bash
+ git clone https://github.com/PaddlePaddle/PaddleNLP.git
+ # pip install ./PaddleNLP 使用develop版本
+ cd PaddleNLP/llm
+ # 到达运行目录
+```
+
+### 2.2 精调数据准备
+
+为了方便用户测试,我们也提供示例数据集[广告生成数据集](https://bj.bcebos.com/paddlenlp/datasets/examples/AdvertiseGen.tar.gz),用户也可以仿照数据集的格式制作自己的数据集进行精调。我们支持的数据格式是每行包含一个字典,每个字典包含以下字段:
+
+- `src` : `str, List(str)`, 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。
+- `tgt` : `str, List(str)`, 模型的输出。
+
+样例数据:
+```
+{"src": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "tgt": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
+...
+```
+
+### 2.3 SFT
+
+SFT(Supervised Fine-Tuning)模型全参微调依托飞桨提出的[4D混合分布式并行](https://ai.baidu.com/forum/topic/show/987996)能力,支持使用Trainer API轻松切换数据并行(DP)、[张量并行(TP, Tensor Parallelism)](https://arxiv.org/abs/1909.08053)、[流水线并行(PP, Pipeline Parallelism)](https://arxiv.org/abs/1811.06965)(目前仅支持Llama)等多种分布式训练策略。
+
+```
+python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" run_finetune.py ./config/llama/sft_argument.json
+```
+
+1. `zero_padding`设为True有助于提高训练效率。建议将`per_device_train_batch_size`设为1,使用`gradient_accumulation_steps`控制batch size,适当调整`max_length`取值。
+2. 设置`use_flash_attention`为True使用FlashAttention。
+3. SFT API支持4D并行策略,可以通过控制`tensor_parallel_degree`、`pipeline_parallel_degree`、 `sharding`、`sharding_parallel_degree`调整
+
+### 2.4 LoRA
+
+```
+# 单卡训练
+python run_finetune.py ./config/llama/lora_argument.json
+
+# 张量并行分布式训练
+python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" run_finetune.py ./config/llama/lora_argument.json
+```
+
+**Note:**
+1. `zero_padding`设为True有助于提高训练效率。建议将`per_device_train_batch_size`设为1,使用`gradient_accumulation_steps`控制batch size,适当调整`max_length`取值。
+2. LoRA策略默认应用在所有Linear层
+3. 可以通过设置`weight_quantize_algo`将主干模型量化低比特,例如'weight_only_int4','weight_only_int8','nf4'或'fp4'。具体参考精调参数介绍
+4. 设置`use_flash_attention`为True使用FlashAttention。
+5. LoRA API支持4D并行策略,可以通过控制`tensor_parallel_degree`、`pipeline_parallel_degree`、 `sharding`、`sharding_parallel_degree`调整并行训练策略,可拓展至**单机LoRA微调千亿模型**。
+6. LoRA策略默认应用在所有Linear层。
+7. 可以通过修改`lora_rank`改变LoRA算法中rank(秩)的值。
+
+### 2.5 Prefix Tuning
+
+```
+# 单卡训练
+python run_finetune.py ./llama/pt_argument.json
+
+# 张量并行分布式训练
+python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" run_finetune.py ./llama/pt_argument.json
+```
+
+**Note:**
+1. `zero_padding`设为True有助于提高训练效率。建议将`per_device_train_batch_size`设为1,使用`gradient_accumulation_steps`控制batch size,适当调整`max_length`取值。
+2. 可以通过设置`weight_quantize_algo`将主干模型量化低比特,例如'weight_only_int4','weight_only_int8','nf4'或'fp4'。具体参考精调参数介绍
+3. 设置`use_flash_attention`为True使用FlashAttention。
+4. Prefix Tuning API支持4D并行策略,可以通过控制`tensor_parallel_degree`、`pipeline_parallel_degree`、 `sharding`、`sharding_parallel_degree`调整并行训练策略,可拓展至**单机LoRA微调千亿模型**。
+5. 可以通过`num_prefix_tokens`控制Prefix Tuning策略中Prefix Token数量。
+
+
+## 3.精调参数介绍
+模型参数(ModelArgument)
+
+- `model_name_or_path`: 预训练模型名称或者本地的模型路径,用于热启模型和分词器,默认为None。每个模型**支持模型权重**详见各模型目录。
+- `use_flash_attention`: 模型是否使用FlashAttention,默认为False。
+- `lora`: 是否开启LoRA微调策略,默认为False。
+- `lora_path`: LoRA参数和配置路径,对LoRA参数进行初始化,默认为None。
+- `lora_rank`: LoRA算法中rank(秩)的值,默认为8。
+- `prefix_tuning`: 是否使用Prefix Tuning策略,默认为False。
+- `num_prefix_tokens`: Prefix Tuning策略中Prefix Token数量,默认为128。
+- `from_aistudio`: 模型权重是否从Aistudio下载,默认为False。
+- `save_to_aistudio`: 模型权重是否保存到Aistudio,默认为False。
+- `aistudio_repo_id`: 模型权重保存到Aistudio的repo id,默认为None。
+- `aistudio_repo_private`: 模型权重保存到Aistudio的repo是否为私有,默认为True。
+- `aistudio_repo_license`: 模型权重保存到Aistudio的repo license,默认为"Apache License 2.0"。
+- `aistudio_token`: 模型权重保存到Aistudio的token,默认为None。如果save_to_aistudio为True,且环境变量没有设置相应token,必须传入。
+- `neftune`: 是否使用[NEFT](https://arxiv.org/abs/2310.05914),进行微调。默认为False。
+- `neftune_noise_alpha`: NEFT alpha参数,默认为5.0。
+
+
+
+数据参数(DataArgument)
+
+- `dataset_name_or_path`: 本地数据集目录或内置数据集名称,默认为None。脚本已适配单文件和多文件,会自己寻找`dataset_name_or_path/train.json` 或者 `dataset_name_or_path/train/*.json`作为训练集文件, 以及`dataset_name_or_path/dev.json` 或者 `dataset_name_or_path/dev/*.json`作为验证集文件。
+- `task_name`: 用于选择内置数据集中的具体任务,默认为None。
+- `eval_with_do_generation`: 在模型效果评估的时候是否调用model.generate,默认为False。设置为True时,指标为ppl, accuracy;设置为False时,指标为BLEU4/Rouge,建议将`metric_for_best_model`设为bleu4。
+- `save_generation_output`: 当`eval_with_do_generation`设为True,是否将生成结果保存在`generated_output.json`文件中,默认为False。
+- `zero_padding`:是否使用Zero Padding数据流(减少Padding冗余计算,大幅提升有效Token计算效率),默认为False。当`eval_with_do_generation`设为True,评估过程不支持Zero Padding数据流。。
+- `src_length`: 模型输入上下文最大token长度,默认为1024。
+- `max_length`:模型输入(上下文+生成内容)的最大token长度, 默认为2048。当`zero_padding`设为True的时候,同时也为Zero Padding数据流模型训练输入最大长度,通常建议设为模型允许输入最大长度,同时`per_device_train_batch_size`设为1,使用`gradient_accumulation_steps`控制batch size。
+- `lazy`:设置为False则使用`MapDataset`,设置为True则使用`IterDataset`,默认为False。对于数据量较大的时候建议设为True,`IterDataset`可以避免一次性将所有数据读入内存,注意需要设置`max_steps`并且`evaluation_strategy`和`save_strategy`设为`steps`
+
+
+
+
+生成参数(GenerateArgument)
+
+注:以下参数仅在`eval_with_do_generation`为True,调用model.generate()时生效。
+
+- `top_k`: “采样”策略中为 top-k 过滤保留的最高概率标记的数量。默认为1,等价于贪心策略。
+- `top_p`:“采样”策略中 top-p 过滤的累积概率。默认为1.0,表示不起作用。
+
+
+训练参数(TrainingArguments)
+
+以下仅介绍TrainingArguments部分常用参数,详情请参见[TrainingArguments文档](https://paddlenlp.readthedocs.io/zh/latest/trainer.html)。
+
+- `output_dir`: 用于保存相关的文件目录,主要包括模型相关文件、训练过程中的checkpoint、分词器相关文件、评估的结果文件,默认为None。
+- `per_device_train_batch_size`: 训练集训练过程批处理大小,对应 micro batch size,默认为8。该参数需要根据具体的数据集来设定,该参数越大,占用显存越高,训练代价越大;反之,占用显存越小,训练速度越快。
+- `gradient_accumulation_steps`:梯度累积步数,顾名思义,就是将多次计算得到的梯度值进行累加,然后一次性进行参数更新,默认为1。等效于将原有训练batch size*gradient_accumulation_steps。
+- `per_device_eval_batch_size`: 验证集批处理大小,对应 micro batch size,默认为8。该参数越大,占用显存越高;该参数越小,占用显存越低。
+- `eval_accumulation_steps`:在将结果移动到CPU之前,累积输出张量的预测步骤数。如果如果未设置,则在移动到CPU之前,整个预测都会在GPU上累积(速度更快需要更多的显存),默认为None。
+- `num_train_epochs`:模型训练的轮次,默认为3。
+- `learning_rate`:优化器的初始学习率,默认为 5e-05。
+- `warmup_steps`: warmup的步数,默认为0。当warmup_steps>0时,会覆盖warmup_ratio的设置。
+- `logging_steps`: 日志打印的频率,仅当logging_strategy=="step"生效,默认为 500。如果希望看到较快的日志反馈或者即时的训练的速度,可以减小logging_steps。
+- `evaluation_strategy`: 评估策略,默认为no。"no":训练期间不进行评估;"steps":在每eval_steps结束进行;"epoch":在每个 epoch 结束时进行。
+- `save_strategy`: 保存策略,默认为no。"no":训练期间不进行评估;"steps":在每eval_steps结束进行;"epoch":在每个 epoch 结束时进行。
+- `fp16`: 是否需要开启FP16训练,开启FP16训练可以加速训练,默认为False。
+- `bf16`: 是否需要开启BF16训练,开启BF16训练可以加速训练,默认为False。
+- `fp16_opt_level`: 可设置O1或者O2,在 O1 级别下,在白名单中的算子将使用 float16/bfloat16 计算,在黑名单中的算子将使用 float32 计算。在 O2 级别下,模型的参数被转换为 float16/bfloat16, 如果算子的浮点型输入全是 float16/bfloat16,算子才会采用 float16/bfloat16 计算,若任意浮点型输入是 float32 类型,算子将采用 float32 计算。默认为O1。
+- `do_train`: 是否打开训练,默认为False。
+- `do_eval`: 是否打开评估,默认为False。
+- `disable_tqdm`: 是否关掉tqdm的进度条,默认为False。如果需要预估整体的训练时长,可以打开该配置,实时观察训练进度。
+- `load_best_model_at_end`: 训练结束后是否加载最优模型,通常与`metric_for_best_model`配合使用,默认为False。
+- `metric_for_best_model`: 最优模型指标,如"accuarcy"等,用于比较模型好坏,默认为None。
+- `recompute`: 重计算,暂支持full策略。开启后可降低显存以达到增大batch size的目的,默认为False。
+- `save_total_limit`: 保留checkpoint的个数,老的checkpoint会被删除,默认为None。
+- `tensor_parallel_degree`: 此参数tensor_parallel_degree表示将一层transformer结构的份数,该方法对通信开销较大, 建议 tensor_parallel_degree<=8, 尽量使用机器内部通信。默认为-1,表示不启用张量并行。
+- `pipeline_parallel_degree`: 表示划分流水线的大小.(假设该参数为4, 模型12层, 则每一个pp stage 包含3层模型) 默认值-1, 表示不启用流水线并行。
+
+
+
+
+## 4.分布式策略参数合并
+
+**如果开启unified_checkpoint则不需要合参**。我们使用张量并行(TP,Tensor Parallelism)和 流水线并行(PP,Pipeline Parallelism)训练过程中,为了节省TP参数合并时间通常在中间checkpoint将参数存储为多个TP和PP参数分片,可以使用提供的分片合并参数脚本进行参数合并。
+
+```
+python merge_tp_and_pp_params.py \
+ --model_name_or_path ./checkpoints/llama_sft_ckpts/checkpoint-100 \
+ --pp 2 --tp 4
+```
+
+脚本参数介绍
+- `model_name_or_path`: 必须,本地的TP模型参数路径,默认为None。
+- `device`: 运行环境,默认为gpu。
+
+
+## 5.LoRA 参数合并
+
+为了后续的**压缩**和**静态图推理**方便,我们提供LoRA参数合并脚本,可以将LoRA参数合并到主干模型并保存相应的权重。
+```
+python merge_lora_params.py \
+ --model_name_or_path ./checkpoints/sft_ckpts \
+ --lora_path ./checkpoints/lora_ckpts \
+ --output_path ./checkpoints/lora_merge \
+ --device "gpu" \
+ --safe_serialization True
+```
+
+脚本参数介绍
+
+- `lora_path`: LoRA参数和配置路径,对LoRA参数进行初始化,默认为None。
+- `model_name_or_path`: 必须,主干模型参数路径,默认为None。
+- `merge_model_path`: 必须,合并参数后保存路径,默认为None。
+- `device`: 运行环境,默认为gpu。
+- `safe_serialization`: 是否保存为safetensor格式,默认为True。
+
diff --git a/docs/llm/docs/inference.md b/docs/llm/docs/inference.md
new file mode 100644
index 000000000000..c34f31e78101
--- /dev/null
+++ b/docs/llm/docs/inference.md
@@ -0,0 +1,248 @@
+# 大模型推理教程
+
+PaddleNLP除了提供常用模型推理外,还提供了高性能推理,内置动态插入和全环节算子融合策略,极大加快并行推理的速度。
+
+git clone 代码到本地,即可开始。
+
+```bash
+ git clone https://github.com/PaddlePaddle/PaddleNLP.git
+ # pip install ./PaddleNLP 使用develop版本
+ cd PaddleNLP/llm
+ # 到达运行目录
+```
+
+## 1. 常用模型推理
+PaddleNLP 提供了动态图推理和静态图推理两种方式,方便用户快速验证模型推理效果(包含LoRA、PrefixTuning)
+
+### 1.1 动态图推理
+```shell
+# 动态图模型推理命令参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --data_file ./data/dev.json --dtype float16
+```
+对于LoRA、PrefixTuning 模型只需额外传入相应的lora_path或prefix_path即可,如:`--lora_path ./checkpoints/llama_lora_ckpts`或`--prefix_path ./checkpoints/llama_prefix_ckpts`,详见推理参数减少。
+
+### 1.2 静态图推理
+
+```shell
+# 静态图模型推理命令参考, LoRA需要先合并参数,Prefix Tuning暂不支持
+# step1 : 静态图导出
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --output_path ./inference --dtype float16
+# step2: 静态图推理
+python ./predict/predictor.py --model_name_or_path ./inference --data_file ./data/dev.json --dtype float16 --mode static
+```
+
+## 2. 高性能模型推理
+
+高性能推理内置动态插入和全环节算子融合策略,隐藏了底层实现的细节,实现了开箱即用高性能并行推理能力。
+
+  +
+
+
+
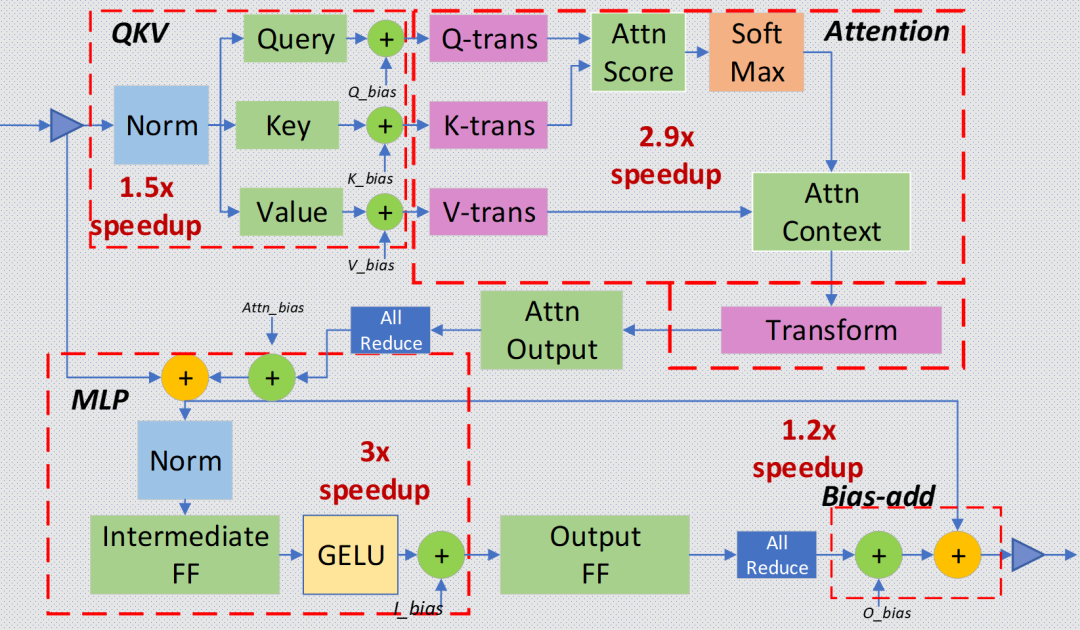
+ 飞桨高性能推理算子融合示意图
+
+
+
+
+  +
+
+
+
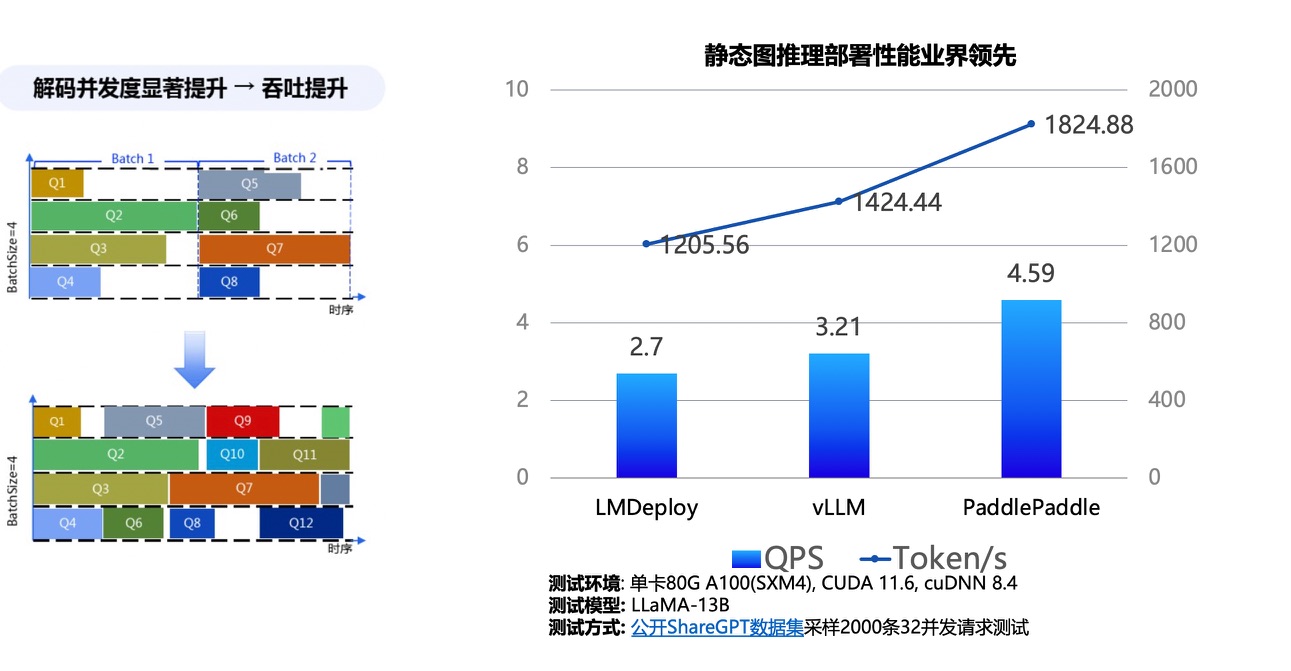
+ 动态插入图解 & 飞桨高性能模型推理性能图
+
+
+
+PaddleNLP 中已经添加高性能推理模型相关实现,支持:
+
+| Model | Inference Model | PTuning | WINT8 | PTQ-A8W8 |
+|----------------------------------|-----------------|---------|-------|----------|
+| [LLaMA1/2](../config/llama) | ✅ | ✅ | ✅ | ✅ |
+| [ChatGLM](../config/chatglm) | ✅ | ✅ | ✅ | ❌ |
+| [ChatGLM2](../config/chatglm2) | ✅ | ❌ | ❌ | ❌ |
+| [Bloom](../config/bloom) | ✅ | ✅ | ✅ | ❌ |
+| [GPT-3](../config/gpt-3) | ✅ | ❌ | ❌ | ❌ |
+| [Qwen](../config/qwen) | ✅ | ❌ | ❌ | ❌ |
+| [BaiChuan-7B](../config/baichuan) | ✅ | ✅ | ✅ | 🚧 |
+| [BaiChuan2-7B](../config/baichuan) | ✅ | ✅ | ✅ | 🚧 |
+| [BaiChuan2-13B](../config/baichuan) | 🚧 | 🚧 | 🚧 | 🚧 |
+
+* ✅: Supported
+* 🚧: In Progress
+* ❌: Not Supported
+* WINT8:指Weight-Only Quantization INT8,即对权重进行INT8量化的模型。
+* PTQ-A8W8:指使用PTQ对线性层的激活和权重都量化为INT8的模型。
+
+为了进一步提升推理的吞吐,我们基于PageAttention的思想设计并实现了BlockAttention,在保持高性能推理和动态插入的基础上可以动态地为cachekv分配存储空间,极大地节省显存,从而在同一时刻处理更多的query以获得吞吐的提升。下面分别给出关闭BlockAttention和打开BlockAttention进行高性能推理的命令参考。
+
+### 2.2 环境准备
+
+- PaddleNLP develop
+- PaddlePaddle develop
+
+PaddleNLP 针对于Transformer 系列编写了高性能自定义算子,提升模型在推理和解码过程中的性能,使用之前需要预先安装自定义算子库:
+
+```shell
+git clone https://github.com/PaddlePaddle/PaddleNLP
+#GPU设备安装自定义算子
+cd ./paddlenlp/csrc && python setup_cuda.py install
+#XPU设备安装自定义算子
+cd ./paddlenlp/csrc/xpu/src && sh cmake_build.sh
+```
+
+### 2.3 关闭BlockAttention的高性能推理
+
+#### 2.3.1 动态图推理
+
+```shell
+# 动态图模型推理命令参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16
+
+# PrefixTuning动态图推理参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --export_precache true --prefix_path ./checkpoints/llama_prefix_ckpts
+
+# Weight Only Int8 动态图推理参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --quant_type weight_only_int8
+
+# PTQ-A8W8推理命令参考
+python ./predict/predictor.py --model_name_or_path checkpoints/llama_ptq_ckpts --inference_model --dtype float16
+```
+**Note**:
+1. LoRA 模型在推理之前是需要合并参数,详细可见:[合并 LoRA 参数](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/tools/merge_lora_params.py)。
+2. PrefixTuning推理需要传入相应的pre_cache,需要额外设置`export_precache`为`true`,并且传入对应的PrefixTuning参数保存路径`prefix_path`。
+3. 使用Weight Only Int8 推理需要额外传入 `quant_type`。
+
+#### 2.3.2 静态图推理
+**step1:动转静**
+```shell
+# 动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16
+
+# PrefixTuning动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --export_precache true
+
+# Weight Only Int8 动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --quant_type weight_only_int8
+
+# PTQ-A8W8动转静命令参考
+python ./predict/export_model.py --model_name_or_path checkpoints/llama_ptq_ckpts --inference_model --output_path ./inference --dtype float16
+```
+**Note**:
+1. LoRA 模型在推理之前是需要合并参数,详细可见:[合并 LoRA 参数](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/tools/merge_lora_params.py)。
+2. PrefixTuning推理需要传入相应的pre_cache,需要额外设置`export_precache`为`true`。
+3. 使用Weight Only Int8 推理需要额外传入 `quant_type`。
+4. A8W8推理传入的 `model_name_or_path` 为PTQ校准产出的量化模型。
+
+**step2:静态图推理**
+```shell
+# 静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --quant_type weight_only_int8 --dtype "float16" --mode "static"
+
+# PrefixTuning静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --quant_type weight_only_int8 --dtype "float16" --mode "static" --export_precache true --prefix_path ./checkpoints/llama_prefix_ckpts
+
+# Weight Only Int8 静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --quant_type weight_only_int8 --dtype "float16" --mode "static" --quant_type weight_only_int8
+
+# PTQ-A8W8静态图推理命令参考
+# 以下环境变量用于开启int8矩阵乘的算法选择以获得更快的推理速度,打开之后第一次执行会执行算法选择从而导致速度较慢。
+export FLAGS_use_autotune=1
+export FLAGS_cublaslt_exhaustive_search_times=10
+export FLAGS_cache_inference_while_scope=1
+
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --quant_type weight_only_int8 --dtype "float16" --mode "static"
+```
+**Note**:
+1. LoRA 模型在推理之前是需要合并参数,详细可见:[合并 LoRA 参数](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/tools/merge_lora_params.py)。
+2. PrefixTuning推理需要传入相应的pre_cache,需要额外设置`export_precache`为`true`,并且传入对应的PrefixTuning参数保存路径`prefix_path`。
+3. 使用Weight Only Int8 推理需要额外传入 `quant_type`。
+4. A8W8推理传入的 `model_name_or_path` 为PTQ校准产出的量化模型。
+
+
+### 2.4 打开BlockAttention的高性能推理
+
+#### 2.4.1 动态图推理
+
+```shell
+# 动态图模型推理命令参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --block_attn
+
+# XPU设备动态图模型推理命令参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --block_attn --device xpu
+
+# Weight Only Int8 动态图推理参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --quant_type weight_only_int8 --block_attn
+
+# PTQ-A8W8推理命令参考
+python ./predict/predictor.py --model_name_or_path checkpoints/llama_ptq_ckpts --inference_model --dtype float16 --block_attn
+
+# CacheKV 动态量化推理命令参考
+python ./predict/predictor.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --dtype float16 --block_attn --cachekv_int8
+```
+
+#### 2.4.2 静态图推理
+**step1:动转静**
+```shell
+# 动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --block_attn
+
+# XPU设备动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --block_attn --device xpu
+
+# Weight Only Int8 动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --quant_type weight_only_int8 --block_attn
+
+# PTQ-A8W8动转静命令参考
+python ./predict/export_model.py --model_name_or_path checkpoints/llama_ptq_ckpts --inference_model --output_path ./inference --dtype float16 --block_attn
+
+# CacheKV 动态量化动转静命令参考
+python ./predict/export_model.py --model_name_or_path meta-llama/Llama-2-7b-chat --inference_model --output_path ./inference --dtype float16 --block_attn --cachekv_int8
+```
+
+**step2:静态图推理**
+```shell
+# 静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --dtype "float16" --mode "static" --block_attn
+
+# XPU设备静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --dtype "float16" --mode "static" --block_attn --device xpu
+
+# Weight Only Int8 静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --dtype "float16" --mode "static" --quant_type weight_only_int8 --block_attn
+
+# PTQ-A8W8静态图推理命令参考
+# 以下环境变量用于开启int8矩阵乘的算法选择以获得更快的推理速度,打开之后第一次执行会执行算法选择从而导致速度较慢。
+export FLAGS_use_autotune=1
+export FLAGS_cublaslt_exhaustive_search_times=10
+export FLAGS_cache_inference_while_scope=1
+
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --dtype "float16" --mode "static" --block_attn
+
+# CacheKV 动态量化8静态图推理命令参考
+python ./predict/predictor.py --model_name_or_path ./inference --inference_model --dtype "float16" --mode "static" --cachekv_int8 --block_attn
+```
+**Note**:
+1. 使用Weight Only Int8 推理需要额外传入 `quant_type`。
+2. A8W8推理传入的 `model_name_or_path` 为PTQ校准产出的量化模型。
+
+
+## 3. 推理参数介绍
+
+- `model_name_or_path`: 必须,预训练模型名称或者本地的模型路径,用于热启模型和分词器,默认为None。
+- `batch_size`: 批处理大小,默认为8。该参数越大,占用显存越高;该参数越小,占用显存越低。
+- `src_length`: 模型输入上下文最大token长度,默认为1024。
+- `max_length`:模型输入(上下文+生成内容)的最大token长度, 默认为2048。
+- `lora_path`: LoRA参数和配置路径,对LoRA参数进行初始化,默认为None。
+- `prefix_path`: Prefix Tuning参数和配置路径,对Prefix Tuning参数进行初始化,默认为None。
+- `top_k`: “采样”策略中为 top-k 过滤保留的最高概率标记的数量。默认为1,等价于贪心策略。
+- `top_p`:“采样”策略中 top-p 过滤的累积概率。默认为1.0,表示不起作用。
+- `temperature`:“采样”策略中会对输出logit除以temperature。默认为1.0,表示不起作用。
+- `data_file`:必须,待推理json文件,默认为None。
+- `output_file`:保存推理结果文件名,默认为output.json。
+- `device`: 运行环境,默认为gpu。
+- `dtype`: 模型参数dtype,默认为None。如果没有传入`lora_path`、`prefix_path`则必须传入
+- `model_type`: 初始化不同类型模型,gpt-3: GPTForCausalLM; ernie-3.5-se: Ernie35ForCausalLM; 默认为 None。
+- `mode`: 使用动态图或者静态图推理,值为:[dynamic, static],默认为 dynamic。
+- `inference_model`: 是否使用Inference Model 推理,默认值为 False。
+- `block_attn`: 是否使用Block Attention 推理, 默认值为False。
+- `block_size`: 如果使用Block Attention 推理,指定一个Block可以存储的token数量,默认值为64。
+- `cachekv_int8`: 是否使用cachekv int8量化用于节省显存,默认值为False。
diff --git a/docs/llm/peft.md b/docs/llm/docs/peft.md
similarity index 99%
rename from docs/llm/peft.md
rename to docs/llm/docs/peft.md
index f720138c6d23..de3b7a65c15b 100644
--- a/docs/llm/peft.md
+++ b/docs/llm/docs/peft.md
@@ -277,4 +277,4 @@ key function
该函数会遍历整个权重参数列表,对于每个权重参数weight,统计所有进行梯度更新的参数,最后将信息打印出来。
```
-更详细的使用可以参考[finetuning 脚本](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/run_finetune.py)版本, 以及对应的启动脚本编写方式(写在 [README.md](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/causallm/README.md)文件中)。
+更详细的使用可以参考[finetuning 脚本](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/run_finetune.py)版本, 以及对应的启动脚本编写方式(写在 [README.md](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/README.md)文件中)。
diff --git a/docs/llm/docs/quantization.md b/docs/llm/docs/quantization.md
new file mode 100644
index 000000000000..eadaa77397a2
--- /dev/null
+++ b/docs/llm/docs/quantization.md
@@ -0,0 +1,111 @@
+# 大模型量化教程
+
+## 1.算法介绍
+
+大模型量化将16位、32位浮点数的模型参数或激活量化为4位或8位整数能够有效降低模型存储空间和计算资源需求,同时加速推理速度。工具链量化算法包含:
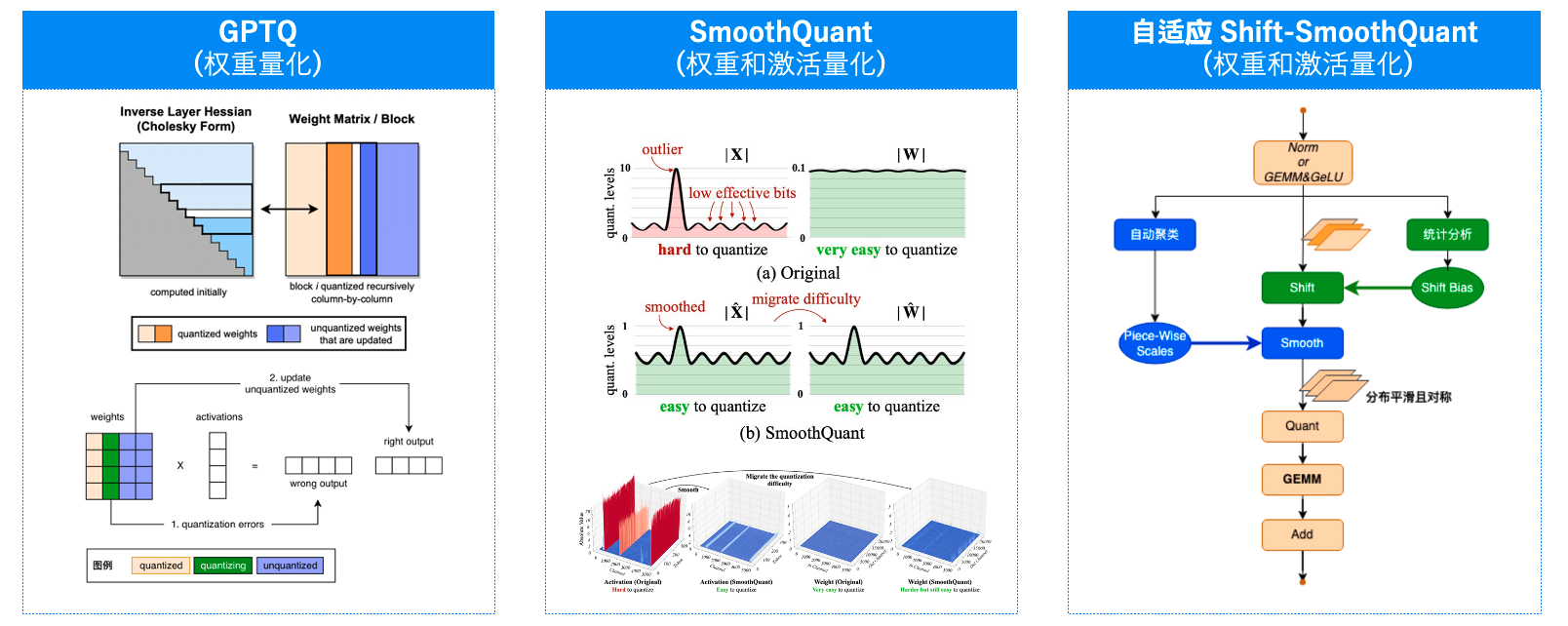
+- **PTQ**。PaddleSlim 团队自研的自适应PiecewiseSearchSmooth(PSS)量化算法,在[SmoothQuant](https://arxiv.org/abs/2211.10438)和[Outlier Suppression+](https://arxiv.org/abs/2304.09145)基础上
+新增PieceWiseSearch参数搜索算法并将算法扩展至**所有线性层**,对模型权重和激活分布进行调整,减少后续A8W8 PTQ量化损失。
+
+
+- **GPTQ**。[GPTQ](https://arxiv.org/abs/2210.17323)是业界主流的权重量化算法,可以将大模型权重进行4位整数无损量化,提高模型推理速度。
+
+- **AWQ**。[GPTQ](https://arxiv.org/abs/2306.00978)是业界主流的权重量化算法,可以将大模型权重进行4位整数无损量化,提高模型推理速度。
+
+
+  +
+
+
+
+ 飞桨大模型量化算法
+
+
+
+更多PaddleSlim实现细节详见[量化策略详细教程](https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/tutorials/quant/advanced_quantization.md)
+
+
+
+## 2. 快速开始
+
+### 2.1 环境准备
+
+- PaddleSlim develop
+- PaddlePaddle develop
+- PaddleNLP develop
+
+git clone 代码到本地,即可开始。
+
+```bash
+ git clone https://github.com/PaddlePaddle/PaddleNLP.git
+ # pip install ./PaddleNLP 使用develop版本
+ cd PaddleNLP/llm
+ # 到达运行目录
+```
+
+### 2.2 数据准备
+
+量化中默认使用训练集作为校正(Calibartion)数据集,开发集作为评估数据集。为了方便用户测试,我们也提供示例数据集[广告生成数据集](https://bj.bcebos.com/paddlenlp/datasets/examples/AdvertiseGen.tar.gz)。如果希望使用其他数据作为校正数据集,则在数据目录下新增`quant.json`文件,用户也可以仿照数据集的格式制作自己的数据集进行精调。我们支持的数据格式是每行包含一个字典,每个字典包含以下字段:
+
+- `src` : `str, List(str)`, 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。
+- `tgt` : `str, List(str)`, 模型的输出。
+
+样例数据:
+```
+{"src": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "tgt": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
+...
+```
+
+
+### 2.3 PTQ 量化
+
+```
+python run_finetune.py ./config/llama/ptq_argument.json
+```
+
+### 2.4 GPTQ 量化
+
+```
+python run_finetune.py ./config/llama/gptq_argument.json
+```
+
+### 2.5 AWQ 量化
+
+```
+python run_finetune.py ./config/llama/awq_argument.json
+```
+
+### 2.6 量化参数介绍
+
+量化参数(QuantArgument)
+
+- `quant_type`: PTQ,QAT量化类型,默认为A8W8。支持A8W8,WINT4,WINT8:A8W8指对激活(输入)进行INT8量化,对模型权重进行INT8量化;WINT4指仅对模型权重进行INT4量化,后续使用WeightOnly进行推理;WINT8指仅对模型权重进行INT8量化,后续使用WeightOnly进行推理。
+- `do_ptq`: 是否进行PTQ量化,默认为False。
+- `weight_quant_method`: 权重量化方式,现可选groupwise或者abs_max_channel_wise。
+- `ptq_step`: PTQ量化步数,也即模型前向次数,默认为32。
+- `shift`: 是否在PTQ量化前进行[Shift策略](https://arxiv.org/abs/2304.09145),默认为False。使用Shift策略需要设`do_ptq`为True。
+- `shift_all_linear`: 是否对模型中所有Linear层应用Shift,如果为True,将会对非LayerNorm-Linear组合的Linear进行Shift,并且添加两个op,默认为False
+- `shift_sampler`: Shift策略使用的sampler,默认为none。可选none,ema:none指直接利用MinMax计算Shift中的零点;ema指使用指数平均计算Shift中零点。
+- `shift_step`: Shift采样步数,也即模型前向次数,默认为32。
+- `smooth`: 是否在PTQ量化前进行[SmoothQuant策略](https://arxiv.org/abs/2211.10438),默认为False。使用Smooth策略需要设`do_ptq`为True。
+- `smooth_all_linears`: 是否对模型中所有Linear层应用Smooth,如果为True,将会对非LayerNorm-Linear组合的Linear进行Smooth,并且添加两个op,默认为False
+- `smooth_sampler`: Smooth策略使用的sampler,默认为none,可选none,multi_step。multi_step会保存多轮前向结果进行计算,需要更大的显存。
+- `smooth_step`: Smooth采样步数,也即模型前向次数,默认为32。
+- `smooth_piecewise_search`: Smooth是否进行分段搜索,默认为False。分段搜索根据数值大小将激活分成K段,对于每一段进行alhpa和scale的搜索。
+- `smooth_k_piece`: 使用分段搜索功能时分段数量,默认为3。根据经验建议10B模型设置为3,100B模型设置为6。
+- `smooth_search_piece`: 使用分段搜索功能时,是否搜索分段数量,默认为False。设为True时,`smooth_k_piece`建议设为6,搜索分段数量耗时较长,如需加速Smooth过程建议关闭。
+- `do_gptq`: 是否进行GPTQ量化,GPTQ对模型进行WINT4量化,相比于普通PTQ量化精度更高,量化时间较长。默认为False。
+- `gptq_step`: GPTQ量化步数,也即模型前向次数,默认为8。
+- `do_awq`: 是否进行AWQ量化,AWQ对模型进行WINT4量化,相比于普通PTQ量化精度更高。默认为False。
+- `auto_clip`: AWQ时是否进行自动搜索截断值并对模型权重进行截断操作,截断操作有利于量化模型精度,但搜索速度较慢。默认为False。
+- `autoclip_step`: AutoClip步数,也即模型前向次数,采样时默认concat每轮数据用来搜索截断值,默认为8。
+
+
+
+
+
+其他参数
+
+- `per_device_train_batch_size`: 量化前向批大小,默认为8。量化过程只有模型前向,相比于普通训练需要显存较少。
+
+更多参数详见[精调文档](./finetune.md)中精调参数介绍。
+
+
diff --git a/docs/llm/docs/torch2paddle.md b/docs/llm/docs/torch2paddle.md
new file mode 100644
index 000000000000..3ca97b65a3b8
--- /dev/null
+++ b/docs/llm/docs/torch2paddle.md
@@ -0,0 +1,55 @@
+# torch2paddle
+
+## 转化 Pytorch 权重
+PaddleNLP 提供了可自动将 PyTorch 相关的权重转化为 Paddle 权重的接口,代码如下:
+
+```python
+from paddlenlp.transformers import AutoModelForCausalLM
+
+AutoModelForCausalLM.from_pretrained("/path/to/pytorch/model", convert_from_torch=True, dtype="float16")
+```
+
+> dtype 为转化权重的真实 dtype 数据类型,通常为:float16, bloat16 和 float32。
+
+以上代码可自动加载 pytorch 权重并转化为对应 paddle 权重保存在 `/path/to/pytorch/model` 目录下。
+
+## 合并 Pytorch 分片权重
+
+当前 PaddleNLP 仅支持转化单个 Pytorch 权重:`pytorch_model.bin`文件。所以当Pytorch 权重为分片权重时,需要将其合并,合并脚本如下所示:
+
+```python
+import torch, os
+state_dict = {}
+
+files = [file for file in os.list("./path/to/pytorch/weight") if file.startswith("pytorch_model-")]
+
+for file in files:
+ state_dict.update(torch.load(file))
+
+torch.save(state_dict, "pytorch_model.bin")
+```
+
+## 支持模型列表
+
+以下为支持权重自动转化的系列模型列表:
+
+| 模型 | 是否支持 |
+|------------|----------|
+| AlBert | ✅ |
+| Bart | ✅ |
+| Bert | ✅ |
+| Bloom | ✅ |
+| Clip | ✅ |
+| DistilBert | ✅ |
+| Electra | ✅ |
+| ErnieCode | ✅ |
+| GLM | ✅ |
+| Gpt | ✅ |
+| Llama | ✅ |
+| Mt5 | ✅ |
+| Opt | ✅ |
+| Qwen | ✅ |
+| Roberta | ✅ |
+| Roformer | ✅ |
+| RW | ✅ |
+| T5 | ✅ |
diff --git a/docs/llm/docs/unified_checkpoint.md b/docs/llm/docs/unified_checkpoint.md
new file mode 100644
index 000000000000..ac0d80f4205a
--- /dev/null
+++ b/docs/llm/docs/unified_checkpoint.md
@@ -0,0 +1,155 @@
+# 飞桨大模型统一存储文档
+
+## 1. 背景
+
+在大模型背景下,通常我们需要进行多卡分布式的训练,在保存Checkpoint时所得到的模型权重通常是分片放置的,例如根据张量并行、流水线并行进行切分保存。这种根据分布式策略直接存储Checkpoint的方式非常直接明了,但也存在如下的问题:
+* 对下游推理不够友好,当用户希望获取中间阶段保存的Checkpoint做下游推理时,需要手动对模型权重进行合并。
+* 不利于应对做恢复训练时,可能会面临的分布式策略改变、训练节点数发生变化的情况。用户往往需要手动对Checkpoint进行处理,增加了操作复杂度。
+
+为了最大程度地解决上述的问题,降低用户操作难度,我们提出了大模型统一存储方案——Unified Checkpoint。Unified Checkpoint的核心思想是将模型权重、优化器权重等进行统一safetensors格式存储,在Checkpoint存储时不再对分布式策略进行区分,提高大模型存储的通用性。以下将首先介绍Unified Checkpoint具体存储格式以及如何使用,随后再简要介绍统一存储的实现原理。
+
+## 2. 统一存储 Unified Checkpoint 使用介绍
+
+### 2.1 使用命令与配置项说明
+
+- **使用示例**
+``` bash
+python -u -m paddle.distributed.launch \
+ --gpus "0,1,2,3,4,5,6,7" \
+ run_pretrain.py \
+ --unified_checkpoint 1 \
+ --unified_checkpoint_config "enable_all_options"
+```
+
+- **总开关**
+`unified_checkpoint`用于控制是否使用Unified Checkpoint存储格式。
+``` bash
+unified_checkpoint: Optional[bool] = field(
+ default=False,
+ metadata={"help": "Whether to unify hybrid parallel checkpoint."},
+)
+```
+
+- **配置项说明**
+``` bash
+unified_checkpoint_config: Optional[str] = field(
+ default="",
+ metadata={
+ "help": (
+ "Configs to unify hybrid parallel checkpoint.\n"
+ "Following options are supports:\n"
+ "- skip_save_model_weight: do not save model weights when the masters weight exist\n"
+ "- master_weight_compatible: 1. if the master weights exist, only load when needed\n"
+ " 2. if master weights does not exist, convert model weights to master weights when needed\n"
+ "- enable_all_options: enable all optimization configurations\n"
+ )
+ },
+)
+```
+介绍如下:
+1. skip_save_model_weight:当optimizer具有master weight时,跳过model weight保存,重启时将master weight作为model weight加载。在PaddleNLP中,仅fp16_opt_level=O1时,optimizer不存在master weight。
+2. master_weight_compatible:仅当optimizer需要master weight时,才加载master weight; 如果ckpt中不存在master weight,将model weight作为master weight加载。
+3. enable_all_options:上述参数均开启。
+
+### 2.2 Unified Checkpoint存储格式介绍
+
+这里以facebook/llama-7b的pretrain checkpoint保存为例进行说明。以TP=4,PP=2的分布式训练为例,原始的存储格式举例如下代码片段。无论是模型参数,异或是优化器参数,均按照TP、PP训练方式进行了分片存储。
+```
+-rw-r--r-- 1 root root 1015 Dec 21 11:27 config.json
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp00_pp00.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp00_pp01.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp01_pp00.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp01_pp01.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp02_pp00.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp02_pp01.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp03_pp00.pdparams
+-rw-r--r-- 1 root root 1.6G Dec 21 11:27 model_state.tp03_pp01.pdparams
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp00_pp00.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp00_pp01.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp01_pp00.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp01_pp01.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp02_pp00.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp02_pp01.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp03_pp00.pdopt
+-rw-r--r-- 1 root root 9.5G Dec 21 11:27 optimizer.tp03_pp01.pdopt
+-rw-r--r-- 1 root root 54K Dec 21 11:27 rng_state_8.pth
+-rw-r--r-- 1 root root 317 Dec 21 11:27 scaler.pdparams
+-rw-r--r-- 1 root root 50 Dec 21 11:27 scheduler.pdparams
+-rw-r--r-- 1 root root 489K Dec 21 11:27 sentencepiece.bpe.model
+-rw-r--r-- 1 root root 63 Dec 21 11:27 special_tokens_map.json
+-rw-r--r-- 1 root root 207 Dec 21 11:27 tokenizer_config.json
+-rw-r--r-- 1 root root 3.1K Dec 21 11:27 trainer_state.json
+-rw-r--r-- 1 root root 2.3K Dec 21 11:27 training_args.bin
+```
+
+采用Unified Checkpoint进行统一存储后,新格式如下面代码片段。可以看到,无论是模型参数、优化器参数,我们均采用了safetensors格式进行存储,不再区分TP、PP策略;进一步地,我们将优化器参数区分为了optimizer与master_weights(如果有的话),而master_weights本身就是模型参数的FP32版本。其中,`model.safetensors.index.json`等json文件用于记录参数对应所在的文件部分。
+```
+-rw-r--r-- 1 root root 1015 Dec 21 11:24 config.json
+-rw-r--r-- 1 root root 3.1G Dec 21 11:25 master_weights-00001-of-00008.safetensors
+-rw-r--r-- 1 root root 3.2G Dec 21 11:25 master_weights-00002-of-00008.safetensors
+-rw-r--r-- 1 root root 3.2G Dec 21 11:25 master_weights-00003-of-00008.safetensors
+-rw-r--r-- 1 root root 3.2G Dec 21 11:25 master_weights-00004-of-00008.safetensors
+-rw-r--r-- 1 root root 3.1G Dec 21 11:25 master_weights-00005-of-00008.safetensors
+-rw-r--r-- 1 root root 3.2G Dec 21 11:25 master_weights-00006-of-00008.safetensors
+-rw-r--r-- 1 root root 3.1G Dec 21 11:25 master_weights-00007-of-00008.safetensors
+-rw-r--r-- 1 root root 3.3G Dec 21 11:25 master_weights-00008-of-00008.safetensors
+-rw-r--r-- 1 root root 28K Dec 21 11:25 master_weights.safetensors.index.json
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00001-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00002-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00003-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00004-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00005-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00006-of-00008.safetensors
+-rw-r--r-- 1 root root 1.6G Dec 21 11:24 model-00007-of-00008.safetensors
+-rw-r--r-- 1 root root 1.7G Dec 21 11:24 model-00008-of-00008.safetensors
+-rw-r--r-- 1 root root 25K Dec 21 11:24 model.safetensors.index.json
+-rw-r--r-- 1 root root 6.2G Dec 21 11:25 optimizer-00001-of-00008.safetensors
+-rw-r--r-- 1 root root 6.4G Dec 21 11:25 optimizer-00002-of-00008.safetensors
+-rw-r--r-- 1 root root 6.2G Dec 21 11:25 optimizer-00003-of-00008.safetensors
+-rw-r--r-- 1 root root 6.4G Dec 21 11:25 optimizer-00004-of-00008.safetensors
+-rw-r--r-- 1 root root 6.3G Dec 21 11:25 optimizer-00005-of-00008.safetensors
+-rw-r--r-- 1 root root 6.4G Dec 21 11:25 optimizer-00006-of-00008.safetensors
+-rw-r--r-- 1 root root 6.3G Dec 21 11:25 optimizer-00007-of-00008.safetensors
+-rw-r--r-- 1 root root 6.4G Dec 21 11:25 optimizer-00008-of-00008.safetensors
+-rw-r--r-- 1 root root 118K Dec 21 11:25 optimizer.safetensors.index.json
+-rw-r--r-- 1 root root 54K Dec 21 11:25 rng_state_8.pth
+-rw-r--r-- 1 root root 317 Dec 21 11:25 scaler.pdparams
+-rw-r--r-- 1 root root 50 Dec 21 11:25 scheduler.pdparams
+-rw-r--r-- 1 root root 489K Dec 21 11:24 sentencepiece.bpe.model
+-rw-r--r-- 1 root root 63 Dec 21 11:24 special_tokens_map.json
+-rw-r--r-- 1 root root 207 Dec 21 11:24 tokenizer_config.json
+-rw-r--r-- 1 root root 3.1K Dec 21 11:25 trainer_state.json
+-rw-r--r-- 1 root root 2.3K Dec 21 11:24 training_args.bin
+```
+
+其中,[safetensors](https://github.com/huggingface/safetensors)是由huggingface开发的一种新序列化格式,旨在简化和精简大型复杂张量的存储和加载。使用Safetensors有很多好处,这里简要列举部分如下:
+1. 速度快:Safetensors采用Zero-copy技术进行了速度优化,可以高效处理大型张量的序列化和反序列化。
+2. 大小优化:混合使用了有效的序列化和压缩算法,以减少大型张量的大小,相比于其他序列化格式(如pickle),性能更快、更高效。
+3. 懒惰加载:Safetensors在加载参数时只需要加载文件中需要的部分张量即可,效率更高。
+4. 安全性:为了防止序列化张量在存储或传输过程中出现损坏,Safetensors使用了校验和机制。这保证了额外的安全性,确保存储在Safetensors中的所有数据都准确可靠。
+
+### 2.3 训练分布式策略发生变化时怎么办?
+
+在Unified checkpoint统一存储格式下,当训练分布式策略不变时,我们直接原地加载Checkpoint进行训练即可。那么,当分布式策略发生变化时,应当怎么做?以下区分两种情况进行讨论。
+
+#### 2.3.1 机器不变
+
+在训练机器不变的情况下,进行分布式策略的改变有多种情况,简单举例如下:
+* 例如单机训练,希望TP=8转为TP=4、Sharding=2进行训练;
+* 例如两机训练时,希望TP=8、Sharding=2转为PP=8、Sharding=2训练;
+* 又或者是希望在相同机器的情况下减少参与训练的进程数(GPU卡数)。
+在这些情况下,我们都不需要对checkpoint进行处理,只需要进行重启操作即可,Unified checkpoint会自动加载文件并执行相应的Tensor切分、发送接收等操作。
+
+#### 2.3.2 机器数量发生变化,例如1->多,多->1,多->多
+
+尽管机器数量发生变化的情况很多,用户在处理Checkpoint时原则上只需要保证:新的训练机器上至少需要有一份完整的Checkpoint参数,这份完整参数可以放置在同一台机器上,也可以分散放置在多台机器上(如果为多机训练的话)。
+* 1->多:例如,原先我们在机器A上训练,Checkpoint存储在A上,接下来想用A、B两台机器同时训练,此时需要确保机器A、B上有一份完整Checkpoint参数即可。
+* 多->1:例如,原先我们在两台机器A、B训练,Checkpoint可能分了两台机器进行存储,接下来想只在机器A上进行训练,那么需要将Checkpoint文件完整放置在机器A上。
+* 多->多:例如,原先我们在机器A、B上训练,Checkpoint存储在A、B上,接下来想用四台机器(A、B、C、D)训练,此时需要确保参与训练的四台机器上具备一份完整Checkpoint参数即可。
+用户只需要确保参与训练的机器上具备一份完整的Checkpoint参数,即可进行重启训练。
+
+#### 2.4 旧格式的Checkpoint如何兼容?
+
+在打开unified_checkpoint开关后,我们会对Checkpoint文件夹中的内容进行检查。
+1. 如果文件夹中具备旧格式的参数文件等,我们会按照旧格式的方式进行参数加载,在后续保存新的Checkpoint时会保存成Unified Checkpoint的格式。
+2. 如果文件夹中不含旧格式参数文件,则默认采用Unified Checkpoint格式进行加载。我们会检查参与训练的机器中的参数文件是否完整,如完整则直接加载训练,否则会进行报错。
diff --git a/docs/llm/finetune.md b/docs/llm/finetune.md
deleted file mode 120000
index 487f6ab2e750..000000000000
--- a/docs/llm/finetune.md
+++ /dev/null
@@ -1 +0,0 @@
-../../llm/docs/finetune.md
\ No newline at end of file
diff --git a/docs/llm/inference.md b/docs/llm/inference.md
deleted file mode 120000
index 888207011440..000000000000
--- a/docs/llm/inference.md
+++ /dev/null
@@ -1 +0,0 @@
-../../llm/docs/inference.md
\ No newline at end of file
diff --git a/docs/llm/pretraining/data/CLUECorpusSmall.md b/docs/llm/pretraining/data/CLUECorpusSmall.md
index 6af9876968f0..473d1f6c4c8f 100644
--- a/docs/llm/pretraining/data/CLUECorpusSmall.md
+++ b/docs/llm/pretraining/data/CLUECorpusSmall.md
@@ -67,7 +67,7 @@ python -u create_pretraining_data.py \
--workers 48
```
-- model_name 可以更换为[其他模型](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/llama/README.md)。
+- model_name 可以更换为[其他模型](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/README.md)。
- workers 表示转化的线程数目
数据共有文档`15702702`条左右,由于分词比较耗时,大概一小时左右可以完成。在当前目录下产出训练所需数据。
diff --git a/docs/llm/pretraining/data/OpenWebText2.md b/docs/llm/pretraining/data/OpenWebText2.md
index 5e7c569c7eca..0264608a953d 100644
--- a/docs/llm/pretraining/data/OpenWebText2.md
+++ b/docs/llm/pretraining/data/OpenWebText2.md
@@ -19,7 +19,7 @@ tar -xvf openwebtext2.jsonl.zst.tar -C /path/to/openwebtext
## Llama训练数据制作
-然后使用[preprocess](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-1.0/preprocess) 工具下的`create_pretraining_data.py`脚本进行数据集制作:
+然后使用[preprocess](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/tools/preprocess) 工具下的`create_pretraining_data.py`脚本进行数据集制作:
```
python -u create_pretraining_data.py \
--model_name meta-llama/Llama-2-7b \
diff --git a/docs/llm/pretraining/dataset.md b/docs/llm/pretraining/dataset.md
index 863009abe152..9984c49f2f75 100644
--- a/docs/llm/pretraining/dataset.md
+++ b/docs/llm/pretraining/dataset.md
@@ -176,10 +176,10 @@ arguments:
## 常用数据集制作
-[CLUECorpus2020 语料制作](docs/CLUECorpus2020.md)
+[CLUECorpus2020 语料制作](./data/CLUECorpus2020.md)
-[CLUECorpusSmall 语料制作](docs/CLUECorpusSmall.md)
+[CLUECorpusSmall 语料制作](./data/CLUECorpusSmall.md)
-[OpenWebText2 语料制作](docs/OpenWebText2.md)
+[OpenWebText2 语料制作](./data/OpenWebText2.md)
-[WuDaoCorpus2.0 Base 语料](docs/WuDaoCorpusBase.md)
+[WuDaoCorpus2.0 Base 语料](./data/WuDaoCorpusBase.md)
diff --git a/docs/llm/quantization.md b/docs/llm/quantization.md
deleted file mode 120000
index 1fd2d59d0ca0..000000000000
--- a/docs/llm/quantization.md
+++ /dev/null
@@ -1 +0,0 @@
-../../llm/docs/quantization.md
\ No newline at end of file
diff --git a/docs/llm/torch2paddle.md b/docs/llm/torch2paddle.md
deleted file mode 120000
index c5a358523e8b..000000000000
--- a/docs/llm/torch2paddle.md
+++ /dev/null
@@ -1 +0,0 @@
-../../llm/docs/torch2paddle.md
\ No newline at end of file
diff --git a/docs/llm/unified_checkpoint.md b/docs/llm/unified_checkpoint.md
deleted file mode 120000
index e4dc95640f29..000000000000
--- a/docs/llm/unified_checkpoint.md
+++ /dev/null
@@ -1 +0,0 @@
-../../llm/docs/unified_checkpoint.md
\ No newline at end of file
diff --git a/docs/locale/en/LC_MESSAGES/advanced_guide/fastgeneration/fastgeneration.po b/docs/locale/en/LC_MESSAGES/advanced_guide/fastgeneration/fastgeneration.po
deleted file mode 100644
index a927bd73636b..000000000000
--- a/docs/locale/en/LC_MESSAGES/advanced_guide/fastgeneration/fastgeneration.po
+++ /dev/null
@@ -1,211 +0,0 @@
-# SOME DESCRIPTIVE TITLE.
-# Copyright (C) 2021, PaddleNLP
-# This file is distributed under the same license as the PaddleNLP package.
-# FIRST AUTHOR  @@ -66,11 +66,11 @@
我们针对不同的数据情况推出三种语义索引方案,如下图所示,您可以参照此方案,快速建立语义索引:
-| ⭐️ 无监督数据 | ⭐️ 有监督数据 | **召回方案** |
-| ------------ | ------------ | ------------ |
-| 多 | 无 | SimCSE |
-| 无 | 多 | In-batch Negatives|
-| 有 | 有 | SimCSE+ In-batch Negatives |
+| ⭐️ 无监督数据 | ⭐️ 有监督数据 | **召回方案** |
+|--------------|--------------|----------------------------|
+| 多 | 无 | SimCSE |
+| 无 | 多 | In-batch Negatives |
+| 有 | 有 | SimCSE+ In-batch Negatives |
最基本的情况是只有无监督数据,我们推荐您使用 SimCSE 进行无监督训练;另一种方案是只有有监督数据,我们推荐您使用 In-batch Negatives 的方法进行有监督训练。
@@ -120,12 +120,12 @@
(4)在排序阶段,使用点击(作为正样本)和展现未点击(作为负样本)数据构造排序阶段的训练集,进行精排训练。
-| 阶段 |模型 | 训练集 | 评估集(用于评估模型效果) | 召回库 |测试集 |
-| ------------ | ------------ |------------ | ------------ | ------------ | ------------ |
-| 召回 | Domain-adaptive Pretraining | 2kw | - | - | - |
-| 召回 | 无监督预训练 - SimCSE | 798w | 20000 | 300000| 1000 |
-| 召回 | 有监督训练 - In-batch Negatives | 3998 | 20000 |300000 | 1000 |
-| 排序 | 有监督训练 - ERNIE-Gram单塔 Pairwise/RocketQA Cross Encoder| 1973538 | 57811 | - | 1000 |
+| 阶段 | 模型 | 训练集 | 评估集(用于评估模型效果) | 召回库 | 测试集 |
+|------|-------------------------------------------------------------|---------|----------------------------|--------|--------|
+| 召回 | Domain-adaptive Pretraining | 2kw | - | - | - |
+| 召回 | 无监督预训练 - SimCSE | 798w | 20000 | 300000 | 1000 |
+| 召回 | 有监督训练 - In-batch Negatives | 3998 | 20000 | 300000 | 1000 |
+| 排序 | 有监督训练 - ERNIE-Gram单塔 Pairwise/RocketQA Cross Encoder | 1973538 | 57811 | - | 1000 |
我们将除 Domain-adaptive Pretraining 之外的其他数据集全部开源,下载地址:
@@ -314,7 +314,7 @@ pip install -r requirements.txt
## 4. Neural Search 快速体验实践
-PaddleNLP已经基于ERNIE 1.0训练了一个基线模型,如果想快速搭建Neural Search的完整系统,有两种方法,第一种是请参考下面的实现,包含了服务化的完整流程,另一种是使用Pipelines加载,Pipelines已经支持Neural Search训练的模型的载入,可以使用Pipelines的快速的基于Neural Search模型实现检索系统,详情请参考文档[Pipelines-Neural-Search](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/semantic-search/Neural_Search.md)。
+PaddleNLP已经基于ERNIE 1.0训练了一个基线模型,如果想快速搭建Neural Search的完整系统,有两种方法,第一种是请参考下面的实现,包含了服务化的完整流程,另一种是使用Pipelines加载,Pipelines已经支持Neural Search训练的模型的载入,可以使用Pipelines的快速的基于Neural Search模型实现检索系统,详情请参考文档[Pipelines-Neural-Search](../../pipelines/examples/semantic-search/Neural_Search.md)。
### 4.1. 召回
@@ -385,14 +385,14 @@ time to cost :0.05616641044616699 seconds
我们进行了多组实践,用来对比说明召回阶段各方案的效果:
-| 模型 | Recall@1 | Recall@5 |Recall@10 |Recall@20 |Recall@50 |策略简要说明|
-| ------------ | ------------ | ------------ |--------- |--------- |--------- |--------- |
-| 有监督训练 Baseline | 30.077| 43.513| 48.633 | 53.448 |59.632| 标准 pair-wise 训练范式,通过随机采样产生负样本|
-| 有监督训练 In-batch Negatives | 51.301 | 65.309| 69.878| 73.996|78.881| In-batch Negatives 有监督训练|
-| 无监督训练 SimCSE | 42.374 | 57.505| 62.641| 67.09|72.331| SimCSE 无监督训练|
-| 无监督 + 有监督训练 SimCSE + In-batch Negatives | 55.976 | 71.849| 76.363| 80.49|84.809| SimCSE无监督训练,In-batch Negatives 有监督训练|
-| Domain-adaptive Pretraining + SimCSE | 51.031 | 66.648| 71.338 | 75.676 |80.144| ERNIE 预训练,SimCSE 无监督训练|
-| Domain-adaptive Pretraining + SimCSE + In-batch Negatives| **58.248** | **75.099**| **79.813**| **83.801**|**87.733**| ERNIE 预训练,SimCSE 无监督训训练,In-batch Negatives 有监督训练|
+| 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 | 策略简要说明 |
+|-----------------------------------------------------------|------------|------------|------------|------------|------------|------------------------------------------------------------------|
+| 有监督训练 Baseline | 30.077 | 43.513 | 48.633 | 53.448 | 59.632 | 标准 pair-wise 训练范式,通过随机采样产生负样本 |
+| 有监督训练 In-batch Negatives | 51.301 | 65.309 | 69.878 | 73.996 | 78.881 | In-batch Negatives 有监督训练 |
+| 无监督训练 SimCSE | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 | SimCSE 无监督训练 |
+| 无监督 + 有监督训练 SimCSE + In-batch Negatives | 55.976 | 71.849 | 76.363 | 80.49 | 84.809 | SimCSE无监督训练,In-batch Negatives 有监督训练 |
+| Domain-adaptive Pretraining + SimCSE | 51.031 | 66.648 | 71.338 | 75.676 | 80.144 | ERNIE 预训练,SimCSE 无监督训练 |
+| Domain-adaptive Pretraining + SimCSE + In-batch Negatives | **58.248** | **75.099** | **79.813** | **83.801** | **87.733** | ERNIE 预训练,SimCSE 无监督训训练,In-batch Negatives 有监督训练 |
从上述表格可以看出,首先利用 ERNIE 3.0 做 Domain-adaptive Pretraining ,然后把训练好的模型加载到 SimCSE 上进行无监督训练,最后利用 In-batch Negatives 在有监督数据上进行训练能够获得最佳的性能。[模型下载](https://paddlenlp.bj.bcebos.com/models/inbatch_model_best.zip),模型的使用方式参考[In-batch Negatives](./recall/in_batch_negative/) 。
@@ -401,7 +401,7 @@ time to cost :0.05616641044616699 seconds
第一步:无监督训练 Domain-adaptive Pretraining
-训练用时 16hour55min,可参考:[ERNIE 1.0](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-1.0)
+训练用时 16hour55min,可参考:[ERNIE 1.0](../../model_zoo/ernie-1.0)
第二步:无监督训练 SimCSE
@@ -453,11 +453,11 @@ time to cost :0.05616641044616699 seconds
排序阶段的效果评估:
-| 模型 | AUC |
-| ------------ | ------------ |
-| Baseline: In-batch Negatives | 0.582 |
-| pairwise ERNIE-Gram |0.801 |
-| CrossEncoder:rocketqa-base-cross-encoder |**0.835** |
+| 模型 | AUC |
+|-------------------------------------------|-----------|
+| Baseline: In-batch Negatives | 0.582 |
+| pairwise ERNIE-Gram | 0.801 |
+| CrossEncoder:rocketqa-base-cross-encoder | **0.835** |
同样输入文本:
diff --git a/legacy/applications/neural_search/recall/simcse/README.md b/legacy/applications/neural_search/recall/simcse/README.md
index 033afd18008f..0173f4538245 100644
--- a/legacy/applications/neural_search/recall/simcse/README.md
+++ b/legacy/applications/neural_search/recall/simcse/README.md
@@ -50,10 +50,10 @@ SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹
**效果评估**
-| 策略 | 模型| Recall@1 | Recall@5 |Recall@10 |Recall@20 |Recall@50 |
-| ------------ | ------------ | ------------ |--------- |--------- |--------- |--------- |
-| SimCSE | ernie 1.0 |42.374 | 57.505| 62.641| 67.09|72.331|
-| SimCSE | rocketqa-zh-base-query-encoder |**50.108** | **64.005**| **68.288**| **72.306**|**77.306**|
+| 策略 | 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 |
+|--------|--------------------------------|------------|------------|------------|------------|------------|
+| SimCSE | ernie 1.0 | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 |
+| SimCSE | rocketqa-zh-base-query-encoder | **50.108** | **64.005** | **68.288** | **72.306** | **77.306** |
@@ -66,11 +66,11 @@
我们针对不同的数据情况推出三种语义索引方案,如下图所示,您可以参照此方案,快速建立语义索引:
-| ⭐️ 无监督数据 | ⭐️ 有监督数据 | **召回方案** |
-| ------------ | ------------ | ------------ |
-| 多 | 无 | SimCSE |
-| 无 | 多 | In-batch Negatives|
-| 有 | 有 | SimCSE+ In-batch Negatives |
+| ⭐️ 无监督数据 | ⭐️ 有监督数据 | **召回方案** |
+|--------------|--------------|----------------------------|
+| 多 | 无 | SimCSE |
+| 无 | 多 | In-batch Negatives |
+| 有 | 有 | SimCSE+ In-batch Negatives |
最基本的情况是只有无监督数据,我们推荐您使用 SimCSE 进行无监督训练;另一种方案是只有有监督数据,我们推荐您使用 In-batch Negatives 的方法进行有监督训练。
@@ -120,12 +120,12 @@
(4)在排序阶段,使用点击(作为正样本)和展现未点击(作为负样本)数据构造排序阶段的训练集,进行精排训练。
-| 阶段 |模型 | 训练集 | 评估集(用于评估模型效果) | 召回库 |测试集 |
-| ------------ | ------------ |------------ | ------------ | ------------ | ------------ |
-| 召回 | Domain-adaptive Pretraining | 2kw | - | - | - |
-| 召回 | 无监督预训练 - SimCSE | 798w | 20000 | 300000| 1000 |
-| 召回 | 有监督训练 - In-batch Negatives | 3998 | 20000 |300000 | 1000 |
-| 排序 | 有监督训练 - ERNIE-Gram单塔 Pairwise/RocketQA Cross Encoder| 1973538 | 57811 | - | 1000 |
+| 阶段 | 模型 | 训练集 | 评估集(用于评估模型效果) | 召回库 | 测试集 |
+|------|-------------------------------------------------------------|---------|----------------------------|--------|--------|
+| 召回 | Domain-adaptive Pretraining | 2kw | - | - | - |
+| 召回 | 无监督预训练 - SimCSE | 798w | 20000 | 300000 | 1000 |
+| 召回 | 有监督训练 - In-batch Negatives | 3998 | 20000 | 300000 | 1000 |
+| 排序 | 有监督训练 - ERNIE-Gram单塔 Pairwise/RocketQA Cross Encoder | 1973538 | 57811 | - | 1000 |
我们将除 Domain-adaptive Pretraining 之外的其他数据集全部开源,下载地址:
@@ -314,7 +314,7 @@ pip install -r requirements.txt
## 4. Neural Search 快速体验实践
-PaddleNLP已经基于ERNIE 1.0训练了一个基线模型,如果想快速搭建Neural Search的完整系统,有两种方法,第一种是请参考下面的实现,包含了服务化的完整流程,另一种是使用Pipelines加载,Pipelines已经支持Neural Search训练的模型的载入,可以使用Pipelines的快速的基于Neural Search模型实现检索系统,详情请参考文档[Pipelines-Neural-Search](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/semantic-search/Neural_Search.md)。
+PaddleNLP已经基于ERNIE 1.0训练了一个基线模型,如果想快速搭建Neural Search的完整系统,有两种方法,第一种是请参考下面的实现,包含了服务化的完整流程,另一种是使用Pipelines加载,Pipelines已经支持Neural Search训练的模型的载入,可以使用Pipelines的快速的基于Neural Search模型实现检索系统,详情请参考文档[Pipelines-Neural-Search](../../pipelines/examples/semantic-search/Neural_Search.md)。
### 4.1. 召回
@@ -385,14 +385,14 @@ time to cost :0.05616641044616699 seconds
我们进行了多组实践,用来对比说明召回阶段各方案的效果:
-| 模型 | Recall@1 | Recall@5 |Recall@10 |Recall@20 |Recall@50 |策略简要说明|
-| ------------ | ------------ | ------------ |--------- |--------- |--------- |--------- |
-| 有监督训练 Baseline | 30.077| 43.513| 48.633 | 53.448 |59.632| 标准 pair-wise 训练范式,通过随机采样产生负样本|
-| 有监督训练 In-batch Negatives | 51.301 | 65.309| 69.878| 73.996|78.881| In-batch Negatives 有监督训练|
-| 无监督训练 SimCSE | 42.374 | 57.505| 62.641| 67.09|72.331| SimCSE 无监督训练|
-| 无监督 + 有监督训练 SimCSE + In-batch Negatives | 55.976 | 71.849| 76.363| 80.49|84.809| SimCSE无监督训练,In-batch Negatives 有监督训练|
-| Domain-adaptive Pretraining + SimCSE | 51.031 | 66.648| 71.338 | 75.676 |80.144| ERNIE 预训练,SimCSE 无监督训练|
-| Domain-adaptive Pretraining + SimCSE + In-batch Negatives| **58.248** | **75.099**| **79.813**| **83.801**|**87.733**| ERNIE 预训练,SimCSE 无监督训训练,In-batch Negatives 有监督训练|
+| 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 | 策略简要说明 |
+|-----------------------------------------------------------|------------|------------|------------|------------|------------|------------------------------------------------------------------|
+| 有监督训练 Baseline | 30.077 | 43.513 | 48.633 | 53.448 | 59.632 | 标准 pair-wise 训练范式,通过随机采样产生负样本 |
+| 有监督训练 In-batch Negatives | 51.301 | 65.309 | 69.878 | 73.996 | 78.881 | In-batch Negatives 有监督训练 |
+| 无监督训练 SimCSE | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 | SimCSE 无监督训练 |
+| 无监督 + 有监督训练 SimCSE + In-batch Negatives | 55.976 | 71.849 | 76.363 | 80.49 | 84.809 | SimCSE无监督训练,In-batch Negatives 有监督训练 |
+| Domain-adaptive Pretraining + SimCSE | 51.031 | 66.648 | 71.338 | 75.676 | 80.144 | ERNIE 预训练,SimCSE 无监督训练 |
+| Domain-adaptive Pretraining + SimCSE + In-batch Negatives | **58.248** | **75.099** | **79.813** | **83.801** | **87.733** | ERNIE 预训练,SimCSE 无监督训训练,In-batch Negatives 有监督训练 |
从上述表格可以看出,首先利用 ERNIE 3.0 做 Domain-adaptive Pretraining ,然后把训练好的模型加载到 SimCSE 上进行无监督训练,最后利用 In-batch Negatives 在有监督数据上进行训练能够获得最佳的性能。[模型下载](https://paddlenlp.bj.bcebos.com/models/inbatch_model_best.zip),模型的使用方式参考[In-batch Negatives](./recall/in_batch_negative/) 。
@@ -401,7 +401,7 @@ time to cost :0.05616641044616699 seconds
第一步:无监督训练 Domain-adaptive Pretraining
-训练用时 16hour55min,可参考:[ERNIE 1.0](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-1.0)
+训练用时 16hour55min,可参考:[ERNIE 1.0](../../model_zoo/ernie-1.0)
第二步:无监督训练 SimCSE
@@ -453,11 +453,11 @@ time to cost :0.05616641044616699 seconds
排序阶段的效果评估:
-| 模型 | AUC |
-| ------------ | ------------ |
-| Baseline: In-batch Negatives | 0.582 |
-| pairwise ERNIE-Gram |0.801 |
-| CrossEncoder:rocketqa-base-cross-encoder |**0.835** |
+| 模型 | AUC |
+|-------------------------------------------|-----------|
+| Baseline: In-batch Negatives | 0.582 |
+| pairwise ERNIE-Gram | 0.801 |
+| CrossEncoder:rocketqa-base-cross-encoder | **0.835** |
同样输入文本:
diff --git a/legacy/applications/neural_search/recall/simcse/README.md b/legacy/applications/neural_search/recall/simcse/README.md
index 033afd18008f..0173f4538245 100644
--- a/legacy/applications/neural_search/recall/simcse/README.md
+++ b/legacy/applications/neural_search/recall/simcse/README.md
@@ -50,10 +50,10 @@ SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹
**效果评估**
-| 策略 | 模型| Recall@1 | Recall@5 |Recall@10 |Recall@20 |Recall@50 |
-| ------------ | ------------ | ------------ |--------- |--------- |--------- |--------- |
-| SimCSE | ernie 1.0 |42.374 | 57.505| 62.641| 67.09|72.331|
-| SimCSE | rocketqa-zh-base-query-encoder |**50.108** | **64.005**| **68.288**| **72.306**|**77.306**|
+| 策略 | 模型 | Recall@1 | Recall@5 | Recall@10 | Recall@20 | Recall@50 |
+|--------|--------------------------------|------------|------------|------------|------------|------------|
+| SimCSE | ernie 1.0 | 42.374 | 57.505 | 62.641 | 67.09 | 72.331 |
+| SimCSE | rocketqa-zh-base-query-encoder | **50.108** | **64.005** | **68.288** | **72.306** | **77.306** |



 -更多的Benchmarks的信息请参考文档[Benchmarks](./benchmarks/README.md)
+更多的Benchmarks的信息请参考文档[Benchmarks](../benchmarks/README.md)
## NLP流水线系统
PaddleNLP Pipelines NLP流水线系统针对 NLP 部分高频场景开源了经过充分打磨的产品级系统,并会不断开放其它场景的产品级系统,用户可以基于NLP流水线系统提供的系统能力快速开发出适配业务数据的产品。
-* 快速搭建产品级[**语义检索**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/semantic-search)系统:使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配
-* 快速搭建产品级[**智能问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/question-answering)系统:用自然语言提问,即可获得精准答案片段
-* 快速搭建产品级 [**FAQ 问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/FAQ)系统:用自然语言提问,匹配相关的高频问题,并返回匹配到的高频问题的答案
+* 快速搭建产品级[**语义检索**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/semantic-search)系统:使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配
+* 快速搭建产品级[**智能问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/question-answering)系统:用自然语言提问,即可获得精准答案片段
+* 快速搭建产品级 [**FAQ 问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/FAQ)系统:用自然语言提问,匹配相关的高频问题,并返回匹配到的高频问题的答案
### 效果展示
@@ -54,16 +54,16 @@ PaddleNLP Pipelines NLP流水线系统针对 NLP 部分高频场景开源了经
-更多的Benchmarks的信息请参考文档[Benchmarks](./benchmarks/README.md)
+更多的Benchmarks的信息请参考文档[Benchmarks](../benchmarks/README.md)
## NLP流水线系统
PaddleNLP Pipelines NLP流水线系统针对 NLP 部分高频场景开源了经过充分打磨的产品级系统,并会不断开放其它场景的产品级系统,用户可以基于NLP流水线系统提供的系统能力快速开发出适配业务数据的产品。
-* 快速搭建产品级[**语义检索**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/semantic-search)系统:使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配
-* 快速搭建产品级[**智能问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/question-answering)系统:用自然语言提问,即可获得精准答案片段
-* 快速搭建产品级 [**FAQ 问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/FAQ)系统:用自然语言提问,匹配相关的高频问题,并返回匹配到的高频问题的答案
+* 快速搭建产品级[**语义检索**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/semantic-search)系统:使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配
+* 快速搭建产品级[**智能问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/question-answering)系统:用自然语言提问,即可获得精准答案片段
+* 快速搭建产品级 [**FAQ 问答**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/examples/FAQ)系统:用自然语言提问,匹配相关的高频问题,并返回匹配到的高频问题的答案
### 效果展示
@@ -54,16 +54,16 @@ PaddleNLP Pipelines NLP流水线系统针对 NLP 部分高频场景开源了经
 -| | |
-|-|-|
-| :floppy_disk: [快速安装](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#floppy_disk-安装) |安装 PaddleNLP Pipelines|
-| :beginner: [快速体验](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#beginner-快速体验) |基于 Pipelines 快速搭建语义检索/智能问答等产品系统|
-| :man_office_worker: [用户案例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#man_office_worker-用户案例) |各行业用户基于PaddleNLP Pipelinse 构建的产品案例|
-| :mortar_board: [Tutorials](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#mortar_board-tutorials) |像搭积木一样一步步构建 NLP 流水线系统教程|
-| :bar_chart: [Benchmarks](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/benchmarks) |针对各场景模型的性能、精度评测指标|
-| :telescope: [Roadmap](https://github.com/PaddlePaddle/PaddleNLP) | PaddleNLP Pipelines 产品路线图|
-| :newspaper: [技术博客](https://github.com/PaddlePaddle/PaddleNLP) | 阅读 PaddleNLP Pipelines 系列技术文章|
-| :vulcan_salute: [社区交流](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#vulcan_salute-社区交流) | [官方微信群](https://github.com/PaddlePaddle/PaddleNLP#社区交流), [GitHub Discussions](https://github.com/PaddlePaddle/PaddleNLP/discussions) |
+| | |
+|------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|
+| :floppy_disk: [快速安装](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#floppy_disk-安装) | 安装 PaddleNLP Pipelines |
+| :beginner: [快速体验](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#beginner-快速体验) | 基于 Pipelines 快速搭建语义检索/智能问答等产品系统 |
+| :man_office_worker: [用户案例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#man_office_worker-用户案例) | 各行业用户基于PaddleNLP Pipelinse 构建的产品案例 |
+| :mortar_board: [Tutorials](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#mortar_board-tutorials) | 像搭积木一样一步步构建 NLP 流水线系统教程 |
+| :bar_chart: [Benchmarks](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/benchmarks) | 针对各场景模型的性能、精度评测指标 |
+| :telescope: [Roadmap](https://github.com/PaddlePaddle/PaddleNLP) | PaddleNLP Pipelines 产品路线图 |
+| :newspaper: [技术博客](https://github.com/PaddlePaddle/PaddleNLP) | 阅读 PaddleNLP Pipelines 系列技术文章 |
+| :vulcan_salute: [社区交流](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#vulcan_salute-社区交流) | [官方微信群](https://github.com/PaddlePaddle/PaddleNLP#社区交流), [GitHub Discussions](https://github.com/PaddlePaddle/PaddleNLP/discussions) |
## :floppy_disk: 安装
Note: 因为 pipelines 依赖较多, 安装耗时大概 10 分钟左右,安装过程中请请耐心等待。
@@ -170,23 +170,23 @@ GPU 镜像下载大概耗时 15 分钟左右,容器启动成功后,等待1
对于国内用户,因为网络问题下载docker比较慢时,可使用百度提供的镜像:
-| 环境 | 镜像 Tag | 运行平台 |
-| :--------------------------: | :-------------------------------: | :-------------: |
-| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0 | Linux |
-| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
-| CUDA10.2 + cuDNN 7 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
-| CUDA11.2 + cuDNN 8 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
+| 环境 | 镜像 Tag | 运行平台 |
+|:------------------:|:----------------------------------------------------------------------:|:-------------:|
+| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0 | Linux |
+| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
+| CUDA10.2 + cuDNN 7 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
+| CUDA11.2 + cuDNN 8 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
如果您的机器不在中国大陆地区,我们推荐您使用DockerHub的镜像:
-| 环境 | 镜像 Tag | 运行平台 |
-| :--------------------------: | :-------------------------------: | :-------------: |
-| CPU | paddlepaddle/paddlenlp:2.4.0 | Linux |
-| CPU | paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
-| CUDA10.2 + cuDNN 7 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
-| CUDA11.2 + cuDNN 8 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
+| 环境 | 镜像 Tag | 运行平台 |
+|:------------------:|:------------------------------------------------:|:-------------:|
+| CPU | paddlepaddle/paddlenlp:2.4.0 | Linux |
+| CPU | paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
+| CUDA10.2 + cuDNN 7 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
+| CUDA11.2 + cuDNN 8 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
-对于智能问答应用,请参考Docker文档[docker文档](./docker/README.md),只需做少量的修改,就可以完成智能问答应用的部署。
+对于智能问答应用,请参考Docker文档[docker文档](../docker/README.md),只需做少量的修改,就可以完成智能问答应用的部署。
#### REST API
@@ -212,10 +212,10 @@ Pipelines可以服务化,通过HTTP接口的形式供其他程序进行调用
市面现已有的工程规范查询系统解决方案一直延续着传统关键字词匹配的查询方式,依赖用户对查询结果进行自行排序、筛选、鉴别,有时甚至还要再次由工程设计人员耗费一定时间精力人工查阅工程规范文件后,才能最终确认是否为想要查询的规范条款。传统规范查询系统至少需要进行 3~5 次查询才能找到用户想要的规范条款,而寻规系统是基于强大预训练模型构建起来的语义检索系统,针对 80% 的规范查询需求仅 **1 次查询** 就能精确命中查询意图,并返回真正符合工程设计人员查询意图的结果!
## :mortar_board: Tutorials
-- Tutorial 1 - Pipelines [Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE/?zw)
-- Tutorial 2 - 语义检索 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442670) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/semantic-search/semantic_search_example.py)
-- Tutorial 3 - 智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442857) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/question-answering/dense_qa_example.py)
-- Tutorial 4 - FAQ智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4465498) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/FAQ/dense_faq_example.py)
+- Tutorial 1 - Pipelines [Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE)
+- Tutorial 2 - 语义检索 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442670) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/semantic-search/semantic_search_example.py)
+- Tutorial 3 - 智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442857) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/question-answering/dense_qa_example.py)
+- Tutorial 4 - FAQ智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4465498) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/FAQ/dense_faq_example.py)
- Tutorial 5 - Pipelines 快速上手二次开发教程: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/5011119)
## :vulcan_salute: 社区交流
微信扫描二维码并填写问卷之后,加入交流群与来自各行各业的小伙伴交流学习吧~
diff --git a/legacy/pipelines/examples/FAQ/README.md b/legacy/pipelines/examples/FAQ/README.md
index 82ac186622a8..703052e46e51 100644
--- a/legacy/pipelines/examples/FAQ/README.md
+++ b/legacy/pipelines/examples/FAQ/README.md
@@ -6,7 +6,7 @@
## 2. 产品功能介绍
-本项目提供了低成本搭建端到端FAQ智能问答的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[FAQ Finance](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/question_answering/supervised_qa/faq_finance),模型的接入流程参考Pipelines语义检索中Neural Search模型接入流程即可。
+本项目提供了低成本搭建端到端FAQ智能问答的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[FAQ Finance](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/question_answering/supervised_qa/faq_finance),模型的接入流程参考Pipelines语义检索中Neural Search模型接入流程即可。
-| | |
-|-|-|
-| :floppy_disk: [快速安装](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#floppy_disk-安装) |安装 PaddleNLP Pipelines|
-| :beginner: [快速体验](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#beginner-快速体验) |基于 Pipelines 快速搭建语义检索/智能问答等产品系统|
-| :man_office_worker: [用户案例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#man_office_worker-用户案例) |各行业用户基于PaddleNLP Pipelinse 构建的产品案例|
-| :mortar_board: [Tutorials](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#mortar_board-tutorials) |像搭积木一样一步步构建 NLP 流水线系统教程|
-| :bar_chart: [Benchmarks](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/benchmarks) |针对各场景模型的性能、精度评测指标|
-| :telescope: [Roadmap](https://github.com/PaddlePaddle/PaddleNLP) | PaddleNLP Pipelines 产品路线图|
-| :newspaper: [技术博客](https://github.com/PaddlePaddle/PaddleNLP) | 阅读 PaddleNLP Pipelines 系列技术文章|
-| :vulcan_salute: [社区交流](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines#vulcan_salute-社区交流) | [官方微信群](https://github.com/PaddlePaddle/PaddleNLP#社区交流), [GitHub Discussions](https://github.com/PaddlePaddle/PaddleNLP/discussions) |
+| | |
+|------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------|
+| :floppy_disk: [快速安装](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#floppy_disk-安装) | 安装 PaddleNLP Pipelines |
+| :beginner: [快速体验](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#beginner-快速体验) | 基于 Pipelines 快速搭建语义检索/智能问答等产品系统 |
+| :man_office_worker: [用户案例](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#man_office_worker-用户案例) | 各行业用户基于PaddleNLP Pipelinse 构建的产品案例 |
+| :mortar_board: [Tutorials](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#mortar_board-tutorials) | 像搭积木一样一步步构建 NLP 流水线系统教程 |
+| :bar_chart: [Benchmarks](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines/benchmarks) | 针对各场景模型的性能、精度评测指标 |
+| :telescope: [Roadmap](https://github.com/PaddlePaddle/PaddleNLP) | PaddleNLP Pipelines 产品路线图 |
+| :newspaper: [技术博客](https://github.com/PaddlePaddle/PaddleNLP) | 阅读 PaddleNLP Pipelines 系列技术文章 |
+| :vulcan_salute: [社区交流](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/pipelines#vulcan_salute-社区交流) | [官方微信群](https://github.com/PaddlePaddle/PaddleNLP#社区交流), [GitHub Discussions](https://github.com/PaddlePaddle/PaddleNLP/discussions) |
## :floppy_disk: 安装
Note: 因为 pipelines 依赖较多, 安装耗时大概 10 分钟左右,安装过程中请请耐心等待。
@@ -170,23 +170,23 @@ GPU 镜像下载大概耗时 15 分钟左右,容器启动成功后,等待1
对于国内用户,因为网络问题下载docker比较慢时,可使用百度提供的镜像:
-| 环境 | 镜像 Tag | 运行平台 |
-| :--------------------------: | :-------------------------------: | :-------------: |
-| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0 | Linux |
-| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
-| CUDA10.2 + cuDNN 7 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
-| CUDA11.2 + cuDNN 8 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
+| 环境 | 镜像 Tag | 运行平台 |
+|:------------------:|:----------------------------------------------------------------------:|:-------------:|
+| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0 | Linux |
+| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
+| CUDA10.2 + cuDNN 7 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
+| CUDA11.2 + cuDNN 8 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
如果您的机器不在中国大陆地区,我们推荐您使用DockerHub的镜像:
-| 环境 | 镜像 Tag | 运行平台 |
-| :--------------------------: | :-------------------------------: | :-------------: |
-| CPU | paddlepaddle/paddlenlp:2.4.0 | Linux |
-| CPU | paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
-| CUDA10.2 + cuDNN 7 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
-| CUDA11.2 + cuDNN 8 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
+| 环境 | 镜像 Tag | 运行平台 |
+|:------------------:|:------------------------------------------------:|:-------------:|
+| CPU | paddlepaddle/paddlenlp:2.4.0 | Linux |
+| CPU | paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
+| CUDA10.2 + cuDNN 7 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
+| CUDA11.2 + cuDNN 8 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
-对于智能问答应用,请参考Docker文档[docker文档](./docker/README.md),只需做少量的修改,就可以完成智能问答应用的部署。
+对于智能问答应用,请参考Docker文档[docker文档](../docker/README.md),只需做少量的修改,就可以完成智能问答应用的部署。
#### REST API
@@ -212,10 +212,10 @@ Pipelines可以服务化,通过HTTP接口的形式供其他程序进行调用
市面现已有的工程规范查询系统解决方案一直延续着传统关键字词匹配的查询方式,依赖用户对查询结果进行自行排序、筛选、鉴别,有时甚至还要再次由工程设计人员耗费一定时间精力人工查阅工程规范文件后,才能最终确认是否为想要查询的规范条款。传统规范查询系统至少需要进行 3~5 次查询才能找到用户想要的规范条款,而寻规系统是基于强大预训练模型构建起来的语义检索系统,针对 80% 的规范查询需求仅 **1 次查询** 就能精确命中查询意图,并返回真正符合工程设计人员查询意图的结果!
## :mortar_board: Tutorials
-- Tutorial 1 - Pipelines [Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE/?zw)
-- Tutorial 2 - 语义检索 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442670) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/semantic-search/semantic_search_example.py)
-- Tutorial 3 - 智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442857) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/question-answering/dense_qa_example.py)
-- Tutorial 4 - FAQ智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4465498) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/FAQ/dense_faq_example.py)
+- Tutorial 1 - Pipelines [Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE)
+- Tutorial 2 - 语义检索 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442670) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/semantic-search/semantic_search_example.py)
+- Tutorial 3 - 智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4442857) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/question-answering/dense_qa_example.py)
+- Tutorial 4 - FAQ智能问答 Pipeline: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/4465498) | [Python](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/legacy/pipelines/examples/FAQ/dense_faq_example.py)
- Tutorial 5 - Pipelines 快速上手二次开发教程: [AIStudio notebook](https://aistudio.baidu.com/aistudio/projectdetail/5011119)
## :vulcan_salute: 社区交流
微信扫描二维码并填写问卷之后,加入交流群与来自各行各业的小伙伴交流学习吧~
diff --git a/legacy/pipelines/examples/FAQ/README.md b/legacy/pipelines/examples/FAQ/README.md
index 82ac186622a8..703052e46e51 100644
--- a/legacy/pipelines/examples/FAQ/README.md
+++ b/legacy/pipelines/examples/FAQ/README.md
@@ -6,7 +6,7 @@
## 2. 产品功能介绍
-本项目提供了低成本搭建端到端FAQ智能问答的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[FAQ Finance](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/question_answering/supervised_qa/faq_finance),模型的接入流程参考Pipelines语义检索中Neural Search模型接入流程即可。
+本项目提供了低成本搭建端到端FAQ智能问答的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[FAQ Finance](https://github.com/PaddlePaddle/PaddleNLP/tree/release/2.8/applications/question_answering/supervised_qa/faq_finance),模型的接入流程参考Pipelines语义检索中Neural Search模型接入流程即可。
 diff --git a/legacy/pipelines/examples/semantic-search/Multi_Recall.md b/legacy/pipelines/examples/semantic-search/Multi_Recall.md
index 014f7bef233e..5627614090f2 100644
--- a/legacy/pipelines/examples/semantic-search/Multi_Recall.md
+++ b/legacy/pipelines/examples/semantic-search/Multi_Recall.md
@@ -54,7 +54,7 @@ cd PaddleNLP/pipelines
【注意】
-- Windows的安装复杂一点,教程请参考:[Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE/?zw)
+- Windows的安装复杂一点,教程请参考:[Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE)
- 以下的所有的流程都只需要在`pipelines`根目录下进行,不需要跳转目录
### 3.2 数据说明
diff --git a/legacy/pipelines/examples/semantic-search/README.md b/legacy/pipelines/examples/semantic-search/README.md
index e3295dd12a11..d2547ccc23d7 100644
--- a/legacy/pipelines/examples/semantic-search/README.md
+++ b/legacy/pipelines/examples/semantic-search/README.md
@@ -17,7 +17,7 @@
## 2. 产品功能介绍
-本项目提供了低成本搭建端到端语义检索系统的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的语义检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[Neural Search](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search),接入流程可以参考[Neural Search的流程](./Neural_Search.md)。
+本项目提供了低成本搭建端到端语义检索系统的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的语义检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[Neural Search](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/applications/neural_search),接入流程可以参考[Neural Search的流程](./Neural_Search.md)。
diff --git a/legacy/pipelines/examples/semantic-search/Multi_Recall.md b/legacy/pipelines/examples/semantic-search/Multi_Recall.md
index 014f7bef233e..5627614090f2 100644
--- a/legacy/pipelines/examples/semantic-search/Multi_Recall.md
+++ b/legacy/pipelines/examples/semantic-search/Multi_Recall.md
@@ -54,7 +54,7 @@ cd PaddleNLP/pipelines
【注意】
-- Windows的安装复杂一点,教程请参考:[Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE/?zw)
+- Windows的安装复杂一点,教程请参考:[Windows视频安装教程](https://www.bilibili.com/video/BV1DY4y1M7HE)
- 以下的所有的流程都只需要在`pipelines`根目录下进行,不需要跳转目录
### 3.2 数据说明
diff --git a/legacy/pipelines/examples/semantic-search/README.md b/legacy/pipelines/examples/semantic-search/README.md
index e3295dd12a11..d2547ccc23d7 100644
--- a/legacy/pipelines/examples/semantic-search/README.md
+++ b/legacy/pipelines/examples/semantic-search/README.md
@@ -17,7 +17,7 @@
## 2. 产品功能介绍
-本项目提供了低成本搭建端到端语义检索系统的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的语义检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[Neural Search](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search),接入流程可以参考[Neural Search的流程](./Neural_Search.md)。
+本项目提供了低成本搭建端到端语义检索系统的能力。用户只需要处理好自己的业务数据,就可以使用本项目预置的语义检索系统模型(召回模型、排序模型)快速搭建一个针对自己业务数据的问答系统,并可以提供 Web 化产品服务。以下是使用预置模型的教程,如果用户想训练并接入自己训练的模型,模型训练可以参考[Neural Search](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/applications/neural_search),接入流程可以参考[Neural Search的流程](./Neural_Search.md)。