From 0e59ba5a01b24cad2eca066fbd43ac6e80d739fc Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Sun, 27 Apr 2025 00:24:47 +0800
Subject: [PATCH 1/7] feat(ppsci): support fuxi for inference
---
README.md | 1 +
docs/index.md | 1 +
docs/zh/examples/fuxi.md | 69 ++++++++++
examples/fuxi/conf/fuxi.yaml | 47 +++++++
examples/fuxi/conf/fuxi_long.yaml | 42 +++++++
examples/fuxi/conf/fuxi_medium.yaml | 42 +++++++
examples/fuxi/conf/fuxi_short.yaml | 42 +++++++
examples/fuxi/predict.py | 188 ++++++++++++++++++++++++++++
examples/fuxi/requirementx.txt | 4 +
examples/fuxi/util.py | 132 +++++++++++++++++++
10 files changed, 568 insertions(+)
create mode 100644 docs/zh/examples/fuxi.md
create mode 100644 examples/fuxi/conf/fuxi.yaml
create mode 100644 examples/fuxi/conf/fuxi_long.yaml
create mode 100644 examples/fuxi/conf/fuxi_medium.yaml
create mode 100644 examples/fuxi/conf/fuxi_short.yaml
create mode 100644 examples/fuxi/predict.py
create mode 100644 examples/fuxi/requirementx.txt
create mode 100644 examples/fuxi/util.py
diff --git a/README.md b/README.md
index eccd5fb1d..a5b425aa1 100644
--- a/README.md
+++ b/README.md
@@ -118,6 +118,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 天气预报 | [GenCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/gencast) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
+| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2304.02948) |
| 天气预报 | [FengWu 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fengwu) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
| 天气预报 | [Pangu-Weather 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/pangu_weather) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
diff --git a/docs/index.md b/docs/index.md
index 37843c8ca..7a636dd96 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -151,6 +151,7 @@
| 天气预报 | [NowCastNet 气象预报](./zh/examples/nowcastnet.md) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](./zh/examples/graphcast.md) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 天气预报 | [GenCast 气象预报](./zh/examples/gencast.md) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
+| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2304.02948) |
| 天气预报 | [FengWu 气象预报](./zh/examples/fengwu.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
| 天气预报 | [Pangu-Weather 气象预报](./zh/examples/pangu_weather.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
diff --git a/docs/zh/examples/fuxi.md b/docs/zh/examples/fuxi.md
new file mode 100644
index 000000000..08e1760b3
--- /dev/null
+++ b/docs/zh/examples/fuxi.md
@@ -0,0 +1,69 @@
+# FuXi
+
+=== "模型训练命令"
+
+ 暂无
+
+=== "模型评估命令"
+
+ 暂无
+
+=== "模型导出命令"
+
+ 暂无
+
+=== "模型推理命令"
+
+ ``` sh
+ cd examples/fuxi
+ # Download sample input data and model weight from https://pan.baidu.com/s/1PDeb-nwUprYtu9AKGnWnNw?pwd=fuxi#list/path=%2F
+ unzip Sample_Data.zip
+ unzip FuXi_EC.zip
+
+
+ # inference
+ pip install -r requirements.txt
+ python predict.py
+ ```
+
+## 1. 背景简介
+
+FuXi 是阿里巴巴达摩院开发的一款级联机器学习天气预报系统,其目标是提供长达15天的全球天气预报。尽管现有先进的机器学习模型在10天预测中已展现出超越传统数值预报系统的性能,但长期预测中误差累积仍然是一个挑战。FuXi 的研发旨在克服这一难题,力求在15天的预测中达到与顶尖数值预报系统(如 ECMWF)整体平均水平相当的精度,其开发基于长达39年的 ECMWF ERA5 再分析数据集。
+
+## 2. 模型原理
+
+FuXi 采用级联模型结构,针对三个连续的预测时间段(0-5天、5-10天和10-15天)分别进行了优化。这种设计旨在减缓长期预测中的误差累积。此外,FuXi 还发展出 FuXi-Extreme 模型,该模型在标准的 FuXi 基础上融入了去噪扩散概率模型 (DDPM), 用于增强前5天地表预报数据的细节和质量。
+
+模型使用预训练权重推理,接下来将介绍模型的推理过程。
+
+## 3. 模型构建
+
+在该案例中,实现了 FuXiPredictor用于ONNX模型的推理:
+
+``` py linenums="74" title="examples/fuxi/predict.py"
+--8<--
+examples/fuxi/predict.py:46:131
+--8<--
+```
+
+FuXi采用级联模型结构,通过`fuxi_short.yaml`、`fuxi_medium.yaml`、`fuxi_long.yaml`来预测三个连续的预测时间段(0-5天、5-10天和10-15天)。
+
+## 4. 结果可视化
+
+使用 ncvue 打开保存的 NetCDF 文件, ncvue 具体说明见[ncvue官方文档](https://github.com/mcuntz/ncvue)
+
+## 5. 完整代码
+
+``` py linenums="1" title="examples/fuxi/predict.py"
+--8<--
+examples/fuxi/predict.py
+--8<--
+```
+
+## 6. 结果展示
+
+example中展示了15天全球天气预报,具体指标可以使用 ncvue 查看。
+
+## 7. 参考资料
+
+- [FuXi: A cascade machine learning forecasting system for 15-day global weather forecast](https://arxiv.org/abs/2306.12873)
diff --git a/examples/fuxi/conf/fuxi.yaml b/examples/fuxi/conf/fuxi.yaml
new file mode 100644
index 000000000..2e6c393e6
--- /dev/null
+++ b/examples/fuxi/conf/fuxi.yaml
@@ -0,0 +1,47 @@
+defaults:
+ - ppsci_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: ./outputs_fuxi
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: infer # running mode: infer
+seed: 2023
+output_dir: ${hydra:run.dir}
+log_freq: 20
+input_file: 'FuXi_EC/20231012-06_input_grib.nc'
+num_steps: [20, 20, 20]
+fuxi_config_dir: './conf/'
+
+# inference settings
+INFER:
+ pretrained_model_path: null
+ export_path: inference/fengwu_v2
+ onnx_path: ${INFER.export_path}.onnx
+ device: gpu
+ engine: onnx
+ precision: fp32
+ ir_optim: false
+ min_subgraph_size: 30
+ gpu_mem: 100
+ gpu_id: 0
+ max_batch_size: 1
+ num_cpu_threads: 10
+ batch_size: 1
+ input_file: './data/input1.npy'
+ num_steps: [20, 20, 20]
diff --git a/examples/fuxi/conf/fuxi_long.yaml b/examples/fuxi/conf/fuxi_long.yaml
new file mode 100644
index 000000000..7646e2582
--- /dev/null
+++ b/examples/fuxi/conf/fuxi_long.yaml
@@ -0,0 +1,42 @@
+defaults:
+ - ppsci_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: ./outputs_fuxi
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: infer # running mode: infer
+seed: 2023
+output_dir: ${hydra:run.dir}
+log_freq: 20
+
+# inference settings
+INFER:
+ pretrained_model_path: null
+ export_path: FuXi_EC/long
+ onnx_path: ${INFER.export_path}.onnx
+ device: gpu
+ engine: onnx
+ precision: fp32
+ ir_optim: false
+ min_subgraph_size: 30
+ gpu_mem: 100
+ gpu_id: 0
+ max_batch_size: 1
+ num_cpu_threads: 10
+ batch_size: 1
diff --git a/examples/fuxi/conf/fuxi_medium.yaml b/examples/fuxi/conf/fuxi_medium.yaml
new file mode 100644
index 000000000..4cb5b9d26
--- /dev/null
+++ b/examples/fuxi/conf/fuxi_medium.yaml
@@ -0,0 +1,42 @@
+defaults:
+ - ppsci_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: ./outputs_fuxi
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: infer # running mode: infer
+seed: 2023
+output_dir: ${hydra:run.dir}
+log_freq: 20
+
+# inference settings
+INFER:
+ pretrained_model_path: null
+ export_path: FuXi_EC/medium
+ onnx_path: ${INFER.export_path}.onnx
+ device: gpu
+ engine: onnx
+ precision: fp32
+ ir_optim: false
+ min_subgraph_size: 30
+ gpu_mem: 100
+ gpu_id: 0
+ max_batch_size: 1
+ num_cpu_threads: 10
+ batch_size: 1
diff --git a/examples/fuxi/conf/fuxi_short.yaml b/examples/fuxi/conf/fuxi_short.yaml
new file mode 100644
index 000000000..6bf45e31b
--- /dev/null
+++ b/examples/fuxi/conf/fuxi_short.yaml
@@ -0,0 +1,42 @@
+defaults:
+ - ppsci_default
+ - INFER: infer_default
+ - hydra/job/config/override_dirname/exclude_keys: exclude_keys_default
+ - _self_
+
+hydra:
+ run:
+ # dynamic output directory according to running time and override name
+ dir: ./outputs_fuxi
+ job:
+ name: ${mode} # name of logfile
+ chdir: false # keep current working directory unchanged
+ callbacks:
+ init_callback:
+ _target_: ppsci.utils.callbacks.InitCallback
+ sweep:
+ # output directory for multirun
+ dir: ${hydra.run.dir}
+ subdir: ./
+
+# general settings
+mode: infer # running mode: infer
+seed: 2023
+output_dir: ${hydra:run.dir}
+log_freq: 20
+
+# inference settings
+INFER:
+ pretrained_model_path: null
+ export_path: FuXi_EC/short
+ onnx_path: ${INFER.export_path}.onnx
+ device: gpu
+ engine: onnx
+ precision: fp32
+ ir_optim: false
+ min_subgraph_size: 30
+ gpu_mem: 100
+ gpu_id: 0
+ max_batch_size: 1
+ num_cpu_threads: 10
+ batch_size: 1
diff --git a/examples/fuxi/predict.py b/examples/fuxi/predict.py
new file mode 100644
index 000000000..9e9584875
--- /dev/null
+++ b/examples/fuxi/predict.py
@@ -0,0 +1,188 @@
+# Copyright (c) 2025 PaddlePaddle Authors. All Rights Reserved.
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+
+# http://www.apache.org/licenses/LICENSE-2.0
+
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import hydra
+import numpy as np
+import paddle
+import pandas as pd
+import xarray as xr
+from omegaconf import DictConfig
+from omegaconf import OmegaConf
+from packaging import version
+from util import save_like
+
+from deploy.python_infer import base
+from ppsci.utils import logger
+
+
+def time_encoding(init_time, total_step, freq=6):
+ init_time = np.array([init_time])
+ tembs = []
+ for i in range(total_step):
+ hours = np.array([pd.Timedelta(hours=t * freq) for t in [i - 1, i, i + 1]])
+ times = init_time[:, None] + hours[None]
+ times = [pd.Period(t, "H") for t in times.reshape(-1)]
+ times = [(p.day_of_year / 366, p.hour / 24) for p in times]
+ temb = np.array(times, dtype=np.float32)
+ temb = np.concatenate([np.sin(temb), np.cos(temb)], axis=-1)
+ temb = temb.reshape(1, -1)
+ tembs.append(temb)
+ return np.stack(tembs)
+
+
+class FuXiPredictor(base.Predictor):
+ """General predictor for FuXi model.
+
+ Args:
+ cfg (DictConfig): Running configuration.
+ """
+
+ def __init__(
+ self,
+ cfg: DictConfig,
+ ):
+ print(f"cfg: {cfg}")
+ assert cfg.INFER.engine == "onnx", "FuXi engine only supports 'onnx'."
+
+ super().__init__(
+ pdmodel_path=None,
+ pdiparams_path=None,
+ device=cfg.INFER.device,
+ engine=cfg.INFER.engine,
+ precision=cfg.INFER.precision,
+ onnx_path=cfg.INFER.onnx_path,
+ ir_optim=cfg.INFER.ir_optim,
+ min_subgraph_size=cfg.INFER.min_subgraph_size,
+ gpu_mem=cfg.INFER.gpu_mem,
+ gpu_id=cfg.INFER.gpu_id,
+ max_batch_size=cfg.INFER.max_batch_size,
+ num_cpu_threads=cfg.INFER.num_cpu_threads,
+ )
+ self.log_freq = cfg.log_freq
+
+ # get input names
+ self.input_names = [
+ input_node.name for input_node in self.predictor.get_inputs()
+ ]
+
+ # get output names
+ self.output_names = [
+ output_node.name for output_node in self.predictor.get_outputs()
+ ]
+
+ self.output_dir = cfg.output_dir
+
+ def predict(
+ self, input_data, tembs, global_step, num_step, data, batch_size: int = 1
+ ):
+ """Predicts the output of the yinglong model for the given input.
+
+ Args:
+ input_data_prev(np.ndarray): Atomospheric data at the first time moment.
+ input_data_next(np.ndarray): Atmospheric data six later.
+ batch_size (int, optional): Batch size, now only support 1. Defaults to 1.
+
+ Returns:
+ List[np.ndarray]: Prediction for next 56 hours.
+ """
+ if batch_size != 1:
+ raise ValueError(
+ f"FuXiPredictor only support batch_size=1, but got {batch_size}"
+ )
+
+ # output_data_list = []
+ # prepare input dict
+ for _ in range(0, num_step):
+ input_dict = {
+ self.input_names[0]: input_data,
+ self.input_names[1]: tembs[global_step],
+ }
+
+ # run predictor
+ new_input = self.predictor.run(None, input_dict)[0]
+ output = new_input[:, -1]
+ save_like(output, data, global_step, self.output_dir)
+
+ # output_data_list.append(output_data)
+ print(
+ f"global_step: {global_step+1:02d}, output: {input_data.min():.2f} {input_data.max():.2f}"
+ )
+ input_data = new_input
+ global_step += 1
+
+ return input_data, global_step
+
+
+def inference(cfg: DictConfig):
+ # log paddlepaddle's version
+ if version.Version(paddle.__version__) != version.Version("0.0.0"):
+ paddle_version = paddle.__version__
+ if version.Version(paddle.__version__) < version.Version("2.6.0"):
+ logger.warning(
+ f"Detected paddlepaddle version is '{paddle_version}', "
+ "currently it is recommended to use release 2.6 or develop version."
+ )
+ else:
+ paddle_version = f"develop({paddle.version.commit[:7]})"
+
+ logger.info(f"Using paddlepaddle {paddle_version}")
+
+ num_steps = cfg.num_steps
+ stages = ["short", "medium", "long"]
+
+ # load data
+ data = xr.open_dataarray(cfg.input_file)
+
+ total_step = sum(num_steps)
+ init_time = pd.to_datetime(data.time.values[-1])
+ tembs = time_encoding(init_time, total_step)
+
+ print(f'init_time: {init_time.strftime(("%Y%m%d-%H"))}')
+ print(f"latitude: {data.lat.values[0]} ~ {data.lat.values[-1]}")
+
+ assert data.lat.values[0] == 90
+ assert data.lat.values[-1] == -90
+
+ input_data = data.values[None]
+
+ step = 0
+ for i, num_step in enumerate(num_steps):
+ print(f"Inference {stages[i]} ...")
+ cfg_path = cfg.fuxi_config_dir + "fuxi_" + stages[i] + ".yaml"
+ config = OmegaConf.load(cfg_path)
+ print(f"predictor_cfg: {config}")
+ predictor = FuXiPredictor(config)
+ # run predictor
+ input_data, step = predictor.predict(
+ input_data=input_data,
+ tembs=tembs,
+ global_step=step,
+ num_step=num_step,
+ data=data,
+ )
+
+ if step > total_step:
+ break
+
+
+@hydra.main(version_base=None, config_path="./conf", config_name="fuxi.yaml")
+def main(cfg: DictConfig):
+ if cfg.mode == "infer":
+ inference(cfg)
+ else:
+ raise ValueError(f"cfg.mode should in ['infer'], but got '{cfg.mode}'")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/examples/fuxi/requirementx.txt b/examples/fuxi/requirementx.txt
new file mode 100644
index 000000000..db204f6ff
--- /dev/null
+++ b/examples/fuxi/requirementx.txt
@@ -0,0 +1,4 @@
+xarray
+dask
+netCDF4
+bottleneck
diff --git a/examples/fuxi/util.py b/examples/fuxi/util.py
new file mode 100644
index 000000000..14008dabe
--- /dev/null
+++ b/examples/fuxi/util.py
@@ -0,0 +1,132 @@
+import os
+
+import numpy as np
+import pandas as pd
+import xarray as xr
+
+__all__ = ["save_like"]
+
+pl_names = ["z", "t", "u", "v", "r"]
+sfc_names = ["t2m", "u10", "v10", "msl", "tp"]
+levels = [50, 100, 150, 200, 250, 300, 400, 500, 600, 700, 850, 925, 1000]
+
+
+def weighted_rmse(out, tgt):
+ wlat = np.cos(np.deg2rad(tgt.lat))
+ wlat /= wlat.mean()
+ error = (out - tgt) ** 2 * wlat
+ return np.sqrt(error.mean(("lat", "lon")))
+
+
+def split_variable(ds, name):
+ if name in sfc_names:
+ v = ds.sel(level=[name])
+ v = v.assign_coords(level=[0])
+ v = v.rename({"level": "level0"})
+ v = v.transpose("member", "level0", "time", "dtime", "lat", "lon")
+ elif name in pl_names:
+ level = [f"{name}{l}" for l in levels]
+ v = ds.sel(level=level)
+ v = v.assign_coords(level=levels)
+ v = v.transpose("member", "level", "time", "dtime", "lat", "lon")
+ return v
+
+
+def save_like(output, input, step, save_dir="", freq=6, split=False):
+ if save_dir:
+ os.makedirs(save_dir, exist_ok=True)
+ step = (step + 1) * freq
+ init_time = pd.to_datetime(input.time.values[-1])
+
+ ds = xr.DataArray(
+ output[None],
+ dims=["time", "step", "level", "lat", "lon"],
+ coords=dict(
+ time=[init_time],
+ step=[step],
+ level=input.level,
+ lat=input.lat.values,
+ lon=input.lon.values,
+ ),
+ ).astype(np.float32)
+
+ if split:
+
+ def rename(name):
+ if name == "tp":
+ return "TP06"
+ elif name == "r":
+ return "RH"
+ return name.upper()
+
+ new_ds = []
+ for k in pl_names + sfc_names:
+ v = split_variable(ds, k)
+ v.name = rename(k)
+ new_ds.append(v)
+ ds = xr.merge(new_ds, compat="no_conflicts")
+
+ save_name = os.path.join(save_dir, f"{step:03d}.nc")
+ # print(f'Save to {save_name} ...')
+ ds.to_netcdf(save_name)
+
+
+def visualize(save_name, vars=[], titles=[], vmin=None, vmax=None):
+ import cartopy.crs as ccrs
+ import matplotlib.pyplot as plt
+
+ fig, ax = plt.subplots(
+ len(vars), 1, figsize=(8, 6), subplot_kw={"projection": ccrs.PlateCarree()}
+ )
+
+ def plot(ax, v, title):
+ v.plot(
+ ax=ax,
+ x="lon",
+ y="lat",
+ vmin=vmin,
+ vmax=vmax,
+ transform=ccrs.PlateCarree(),
+ add_colorbar=False,
+ )
+ # ax.coastlines()
+ ax.set_title(title)
+ gl = ax.gridlines(draw_labels=True, linewidth=0.5)
+ gl.top_labels = False
+ gl.right_labels = False
+
+ for i, v in enumerate(vars):
+ if len(vars) == 1:
+ plot(ax, v, titles[i])
+ else:
+ plot(ax[i], v, titles[i])
+
+ plt.savefig(
+ save_name, bbox_inches="tight", pad_inches=0.1, transparent="true", dpi=200
+ )
+ plt.close()
+
+
+def test_visualize(step, data_dir):
+ src_name = os.path.join(data_dir, f"{step:03d}.nc")
+ ds = xr.open_dataarray(src_name).isel(time=0)
+ ds = ds.sel(lon=slice(90, 150), lat=slice(50, 0))
+ print(ds)
+ u850 = ds.sel(level="U850", step=step)
+ v850 = ds.sel(level="V850", step=step)
+ ws850 = np.sqrt(u850**2 + v850**2)
+ visualize(
+ f"ws850/{step:03d}.jpg", [ws850], [f"20230725-18+{step:03d}h"], vmin=0, vmax=30
+ )
+
+
+def test_rmse(output_name, target_name):
+ output = xr.open_dataarray(output_name)
+ output = output.isel(time=0).sel(step=120)
+ target = xr.open_dataarray(target_name)
+
+ for level in ["z500", "t850", "t2m", "u10", "v10", "msl", "tp"]:
+ out = output.sel(level=level)
+ tgt = target.sel(level=level)
+ rmse = weighted_rmse(out, tgt).load()
+ print(f"{level.upper()} 120h rmse: {rmse:.3f}")
From dd920d1f0c694b349c48d3805e6fc6eb211a275d Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Tue, 6 May 2025 23:22:25 +0800
Subject: [PATCH 2/7] feat(ppsci): support fuxi for inference
---
README.md | 2 +-
docs/index.md | 2 +-
docs/zh/examples/fuxi.md | 39 ++++++++++++++++---
examples/fuxi/conf/fuxi.yaml | 18 ---------
examples/fuxi/predict.py | 8 ++--
.../{requirementx.txt => requirements.txt} | 4 +-
6 files changed, 41 insertions(+), 32 deletions(-)
rename examples/fuxi/{requirementx.txt => requirements.txt} (100%)
diff --git a/README.md b/README.md
index a5b425aa1..3db545c09 100644
--- a/README.md
+++ b/README.md
@@ -118,7 +118,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 天气预报 | [GenCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/gencast) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
-| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2304.02948) |
+| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2306.12873) |
| 天气预报 | [FengWu 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fengwu) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
| 天气预报 | [Pangu-Weather 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/pangu_weather) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
diff --git a/docs/index.md b/docs/index.md
index 7a636dd96..46bb949d0 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -151,7 +151,7 @@
| 天气预报 | [NowCastNet 气象预报](./zh/examples/nowcastnet.md) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](./zh/examples/graphcast.md) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 天气预报 | [GenCast 气象预报](./zh/examples/gencast.md) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
-| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2304.02948) |
+| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2306.12873) |
| 天气预报 | [FengWu 气象预报](./zh/examples/fengwu.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
| 天气预报 | [Pangu-Weather 气象预报](./zh/examples/pangu_weather.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
diff --git a/docs/zh/examples/fuxi.md b/docs/zh/examples/fuxi.md
index 08e1760b3..4baa4b486 100644
--- a/docs/zh/examples/fuxi.md
+++ b/docs/zh/examples/fuxi.md
@@ -20,7 +20,6 @@
unzip Sample_Data.zip
unzip FuXi_EC.zip
-
# inference
pip install -r requirements.txt
python predict.py
@@ -28,11 +27,34 @@
## 1. 背景简介
-FuXi 是阿里巴巴达摩院开发的一款级联机器学习天气预报系统,其目标是提供长达15天的全球天气预报。尽管现有先进的机器学习模型在10天预测中已展现出超越传统数值预报系统的性能,但长期预测中误差累积仍然是一个挑战。FuXi 的研发旨在克服这一难题,力求在15天的预测中达到与顶尖数值预报系统(如 ECMWF)整体平均水平相当的精度,其开发基于长达39年的 ECMWF ERA5 再分析数据集。
+FuXi模型是一个机器学习(ML)天气预报系统,旨在生成15天的全球天气预报。它利用了39年的欧洲中期天气预报中心(ECMWF)ERA5再分析数据集,这些数据具有0.25°的空间分辨率和6小时的时间分辨率。FuXi系统的命名来源于中国古代神话中的人物伏羲,他被认为是中国的第一个天气预报员。
+
+FuXi模型开发的关键方面和背景包括:
+
+- 动机:FuXi的开发是出于对当前ML模型在长期天气预报中由于误差累积而产生的局限性的考虑。虽然ML模型在短期预报中已经显示出前景,但在长期预报(例如15天)中实现与欧洲中期天气预报中心(ECMWF)的传统数值天气预报(NWP)模型相当的性能仍然是一个挑战。
+
+- Cascade模型架构:为了解决误差累积的问题,FuXi采用了一种新颖的Cascade ML模型架构。这种架构使用针对特定5天预报时间窗口(0-5天、5-10天和10-15天)优化的预训练模型,以提高不同预报时效的准确性。
+
+- 基础模型: FuXi的基础模型是一个自动回归模型,旨在从高维天气数据中提取复杂特征并学习关系。
+
+- 训练过程:FuXi的训练过程包括预训练和微调两个步骤。预训练步骤优化模型以预测单个时间步,而微调则涉及训练Cascade模型以用于它们各自的预报时间窗口。
+
+- 性能:FuXi系统在15天预报中表现出与ECMWF集合平均(EM)相当的性能,并且在有效预报时效方面优于ECMWF高分辨率预报(HRES)。
+
+FuXi模型使用了第五代ECMWF再分析数据集ERA5。该数据集提供了从1940年1月至今的地表和高空参数的逐小时数据。ERA5数据集是通过同化使用ECMWF的集成预报系统(IFS)模型获得的高质量和丰富的全球观测资料而生成的。 ERA5数据被广泛认为是全面而准确的再分析档案,这使其适合作为训练FuXi模型的地面实况。对于FuXi模型,使用了ERA5数据集的一个子集,该子集跨越39年,具有0.25°的空间分辨率和6小时的时间分辨率。 该模型旨在预测13个压力层的5个高空大气变量和5个地表变量。
+数据集被分为训练集、验证集和测试集。训练集包含1979年至2015年的54020个样本,验证集包含2016年和2017年的2920个样本,样本外测试集包含2018年的1460个样本。此外,还创建了两个参考数据集HRES-fc0和ENS-fc0,以评估ECMWF高分辨率预报(HRES)和集合平均(EM)的性能。
## 2. 模型原理
-FuXi 采用级联模型结构,针对三个连续的预测时间段(0-5天、5-10天和10-15天)分别进行了优化。这种设计旨在减缓长期预测中的误差累积。此外,FuXi 还发展出 FuXi-Extreme 模型,该模型在标准的 FuXi 基础上融入了去噪扩散概率模型 (DDPM), 用于增强前5天地表预报数据的细节和质量。
+FuXi模型是一种自回归模型,它利用前两个时间步的天气参数(Xt-1, Xt)作为输入,来预测下一个时间步的天气参数(Xt+1)。其中,t、t-1和t+1分别代表当前、前一个和下一个时间步。本模型中使用的时间步长为6小时。通过将模型的输出用作后续预测的输入,该系统可以生成不同预报时效的预报。
+
+使用单个FuXi模型生成15天预报需要进行60次迭代。与基于物理的NWP模型不同,纯数据驱动的ML模型缺乏物理约束,这可能导致长期预报的误差显著增长和不切实际的预测结果。使用自回归多步损失可以有效减少长期预报的累积误差。这种损失函数类似于四维变分数据同化(4D-Var)方法中使用的成本函数,其目的是识别在同化时间窗内与观测结果最佳拟合的初始天气条件。虽然增加自回归步数可以提高长期预报的准确性,但也会降低短期预报的准确性。此外,与增加4D-Var的同化时间窗类似,增加自回归步数需要更多的内存和计算资源来处理训练过程中的梯度。
+
+在进行迭代预报时,随着预报时效的增加,误差累积是不可避免的。此外,先前的研究表明,单个模型无法在所有预报时效都达到最佳性能。为了优化短期和长期预报的性能,论文提出了一种使用预训练FuXi模型的Cascade模型架构,这些模型经过微调,以在特定的5天预报时间窗内实现最佳性能。这些时间窗被称为FuXi-Short(0-5天)、FuXi-Medium(5-10天)和FuXi-Long(10-15天)。FuXi-Short和FuXi-Medium的输出分别在第20步和第40步被用作FuXi-Medium和FuXi-Long的输入。与Pangu-Weather中使用的贪婪分层时间聚合策略(该策略利用4个分别预测1小时、3小时、6小时和24小时预报时效的模型来减少步数)不同,Cascade FuXi模型不存在时间不一致的问题。
+
+基础FuXi模型的模型架构由三个主要部分组成,如论文所诉:Cube Embedding、U-Transformer和全连接(FC)层。输入数据结合了高空和地面变量,并创建了一个维度为2×70×721×1440的数据立方体,其中2代表前两个时间步(t-1和t),70代表输入变量的总数,721和1440分别代表纬度(H)和经度(W)网格点。
+
+首先,高维输入数据通过联合时空Cube Embedding被降维到C×180×360,其中C是通道数,设置为1536。Cube Embedding的主要目的是减少输入数据的时间和空间维度,降低数据冗余度。随后,U-Transformer处理嵌入后的数据,并使用一个简单的FC层进行预测。输出结果首先被reshape为70×720×1440,然后通过双线性插值恢复到原始输入形状70×721×1440。
模型使用预训练权重推理,接下来将介绍模型的推理过程。
@@ -42,7 +64,7 @@ FuXi 采用级联模型结构,针对三个连续的预测时间段(0-5天、
``` py linenums="74" title="examples/fuxi/predict.py"
--8<--
-examples/fuxi/predict.py:46:131
+examples/fuxi/predict.py:44:121
--8<--
```
@@ -62,7 +84,14 @@ examples/fuxi/predict.py
## 6. 结果展示
-example中展示了15天全球天气预报,具体指标可以使用 ncvue 查看。
+模型推理结果包含 60 个 NetCDF 文件,表示从预测时间点开始,未来 15 天内每个模型20个时间步的气象数据。
+
+1. 安装相关依赖
+```python
+pip install cdsapi netCDF4 ncvue
+```
+
+2. 使用 ncvue 打开转换后的 NetCDF 文件, ncvue 具体说明见[ncvue官方文档](https://github.com/mcuntz/ncvue)
## 7. 参考资料
diff --git a/examples/fuxi/conf/fuxi.yaml b/examples/fuxi/conf/fuxi.yaml
index 2e6c393e6..a113d0db2 100644
--- a/examples/fuxi/conf/fuxi.yaml
+++ b/examples/fuxi/conf/fuxi.yaml
@@ -27,21 +27,3 @@ log_freq: 20
input_file: 'FuXi_EC/20231012-06_input_grib.nc'
num_steps: [20, 20, 20]
fuxi_config_dir: './conf/'
-
-# inference settings
-INFER:
- pretrained_model_path: null
- export_path: inference/fengwu_v2
- onnx_path: ${INFER.export_path}.onnx
- device: gpu
- engine: onnx
- precision: fp32
- ir_optim: false
- min_subgraph_size: 30
- gpu_mem: 100
- gpu_id: 0
- max_batch_size: 1
- num_cpu_threads: 10
- batch_size: 1
- input_file: './data/input1.npy'
- num_steps: [20, 20, 20]
diff --git a/examples/fuxi/predict.py b/examples/fuxi/predict.py
index 9e9584875..12d6bf43b 100644
--- a/examples/fuxi/predict.py
+++ b/examples/fuxi/predict.py
@@ -84,7 +84,7 @@ def __init__(
self.output_dir = cfg.output_dir
def predict(
- self, input_data, tembs, global_step, num_step, data, batch_size: int = 1
+ self, input_data, tembs, global_step, stage, num_step, data, batch_size: int = 1
):
"""Predicts the output of the yinglong model for the given input.
@@ -101,7 +101,6 @@ def predict(
f"FuXiPredictor only support batch_size=1, but got {batch_size}"
)
- # output_data_list = []
# prepare input dict
for _ in range(0, num_step):
input_dict = {
@@ -113,10 +112,8 @@ def predict(
new_input = self.predictor.run(None, input_dict)[0]
output = new_input[:, -1]
save_like(output, data, global_step, self.output_dir)
-
- # output_data_list.append(output_data)
print(
- f"global_step: {global_step+1:02d}, output: {input_data.min():.2f} {input_data.max():.2f}"
+ f"stage: {stage}, global_step: {global_step+1:02d}, output: {output.min():.2f} {output.max():.2f}"
)
input_data = new_input
global_step += 1
@@ -168,6 +165,7 @@ def inference(cfg: DictConfig):
input_data=input_data,
tembs=tembs,
global_step=step,
+ stage=i,
num_step=num_step,
data=data,
)
diff --git a/examples/fuxi/requirementx.txt b/examples/fuxi/requirements.txt
similarity index 100%
rename from examples/fuxi/requirementx.txt
rename to examples/fuxi/requirements.txt
index db204f6ff..8ebbfb50f 100644
--- a/examples/fuxi/requirementx.txt
+++ b/examples/fuxi/requirements.txt
@@ -1,4 +1,4 @@
-xarray
+bottleneck
dask
netCDF4
-bottleneck
+xarray
From 2228ad1544e35d8386201088ad67a002e852feea Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Wed, 7 May 2025 23:03:44 +0800
Subject: [PATCH 3/7] feat(ppsci): support fuxi for inference
---
docs/zh/examples/fuxi.md | 23 +++++++--
examples/fuxi/requirements.txt | 1 +
examples/fuxi/visualize.py | 93 ++++++++++++++++++++++++++++++++++
3 files changed, 112 insertions(+), 5 deletions(-)
create mode 100644 examples/fuxi/visualize.py
diff --git a/docs/zh/examples/fuxi.md b/docs/zh/examples/fuxi.md
index 4baa4b486..fd994b26a 100644
--- a/docs/zh/examples/fuxi.md
+++ b/docs/zh/examples/fuxi.md
@@ -20,7 +20,7 @@
unzip Sample_Data.zip
unzip FuXi_EC.zip
- # inference
+ # modify the path of model and datasets in examples/fuxi/conf, and inference
pip install -r requirements.txt
python predict.py
```
@@ -41,6 +41,13 @@ FuXi模型开发的关键方面和背景包括:
- 性能:FuXi系统在15天预报中表现出与ECMWF集合平均(EM)相当的性能,并且在有效预报时效方面优于ECMWF高分辨率预报(HRES)。
+模型的总体结构如图所示:
+
+
+ 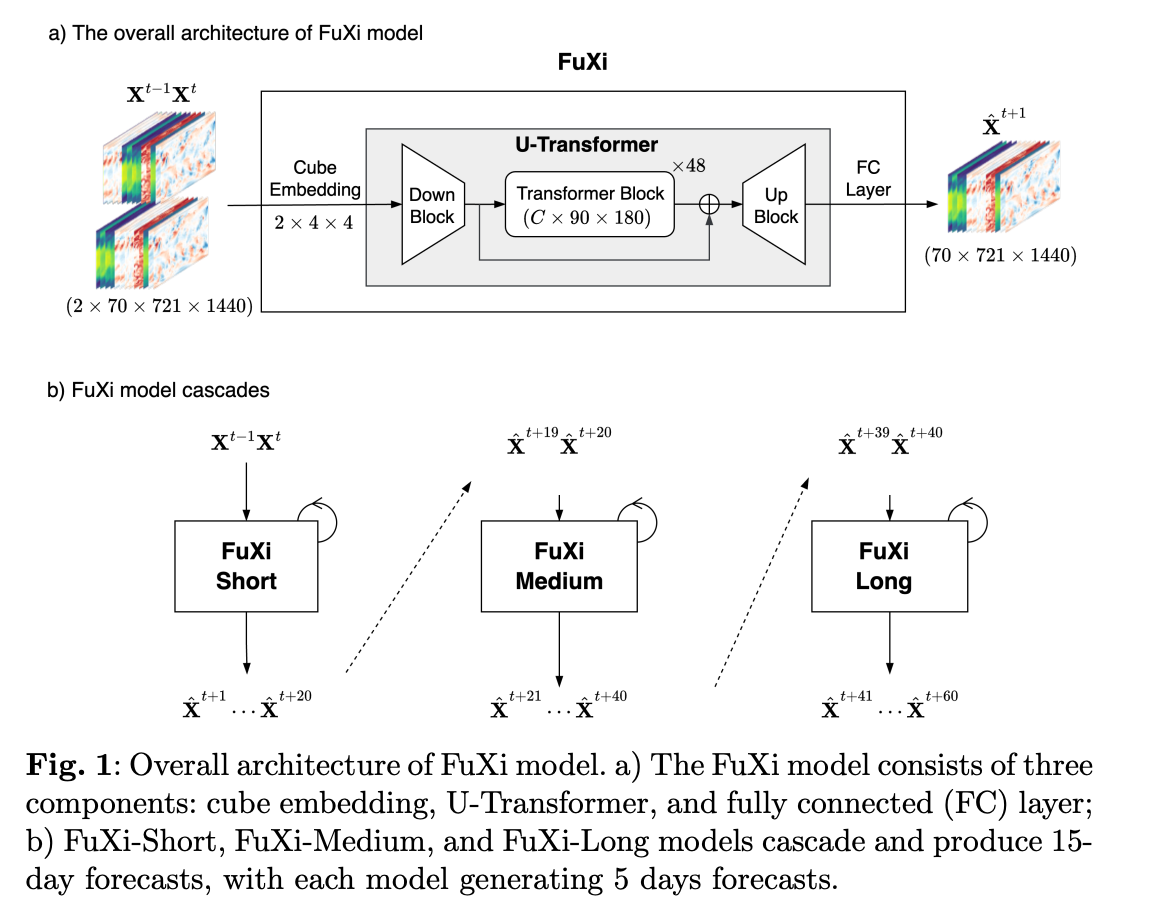{ loading=lazy style="margin:0 auto;"}
+ 模型结构
+
+
FuXi模型使用了第五代ECMWF再分析数据集ERA5。该数据集提供了从1940年1月至今的地表和高空参数的逐小时数据。ERA5数据集是通过同化使用ECMWF的集成预报系统(IFS)模型获得的高质量和丰富的全球观测资料而生成的。 ERA5数据被广泛认为是全面而准确的再分析档案,这使其适合作为训练FuXi模型的地面实况。对于FuXi模型,使用了ERA5数据集的一个子集,该子集跨越39年,具有0.25°的空间分辨率和6小时的时间分辨率。 该模型旨在预测13个压力层的5个高空大气变量和5个地表变量。
数据集被分为训练集、验证集和测试集。训练集包含1979年至2015年的54020个样本,验证集包含2016年和2017年的2920个样本,样本外测试集包含2018年的1460个样本。此外,还创建了两个参考数据集HRES-fc0和ENS-fc0,以评估ECMWF高分辨率预报(HRES)和集合平均(EM)的性能。
@@ -72,7 +79,7 @@ FuXi采用级联模型结构,通过`fuxi_short.yaml`、`fuxi_medium.yaml`、`f
## 4. 结果可视化
-使用 ncvue 打开保存的 NetCDF 文件, ncvue 具体说明见[ncvue官方文档](https://github.com/mcuntz/ncvue)
+使用 `examples/fuxi/predict.py` 进行画图,进行结果可视化。
## 5. 完整代码
@@ -86,12 +93,18 @@ examples/fuxi/predict.py
模型推理结果包含 60 个 NetCDF 文件,表示从预测时间点开始,未来 15 天内每个模型20个时间步的气象数据。
-1. 安装相关依赖
+使用 `examples/fuxi/predict.py` 进行画图,进行结果可视化。
+
```python
-pip install cdsapi netCDF4 ncvue
+python3.10 visualize.py --data_dir outputs_fuxi_pd/ --save_dir outputs_fuxi_pd/ --step 6
```
-2. 使用 ncvue 打开转换后的 NetCDF 文件, ncvue 具体说明见[ncvue官方文档](https://github.com/mcuntz/ncvue)
+下图展示了
+
+
+ 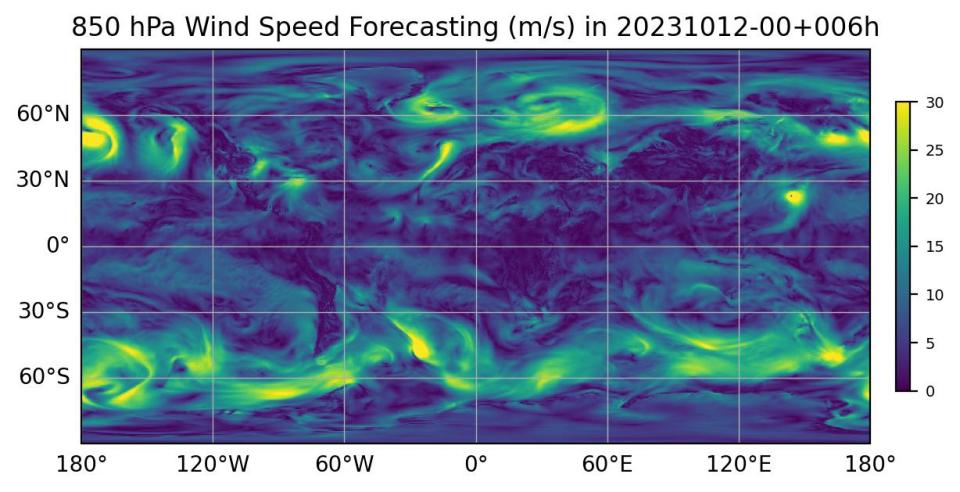{ loading=lazy style="margin:0 auto;"}
+ 未来6小时天气预测结果
+
## 7. 参考资料
diff --git a/examples/fuxi/requirements.txt b/examples/fuxi/requirements.txt
index 8ebbfb50f..84375f3c1 100644
--- a/examples/fuxi/requirements.txt
+++ b/examples/fuxi/requirements.txt
@@ -1,4 +1,5 @@
bottleneck
+cartopy
dask
netCDF4
xarray
diff --git a/examples/fuxi/visualize.py b/examples/fuxi/visualize.py
new file mode 100644
index 000000000..a36f3afc1
--- /dev/null
+++ b/examples/fuxi/visualize.py
@@ -0,0 +1,93 @@
+import argparse
+import os
+
+import numpy as np
+import xarray as xr
+
+
+def visualize(save_name, vars=[], titles=[], vmin=None, vmax=None):
+ import cartopy.crs as ccrs
+ import matplotlib.pyplot as plt
+
+ fig_height = 4 if len(vars) == 1 else 4 * len(vars)
+ fig, ax = plt.subplots(
+ len(vars),
+ 1,
+ figsize=(7, fig_height),
+ subplot_kw={"projection": ccrs.PlateCarree()},
+ )
+
+ plt.subplots_adjust(hspace=0.25)
+
+ def plot(ax, v, title):
+ im = v.plot(
+ ax=ax,
+ x="lon",
+ y="lat",
+ vmin=vmin,
+ vmax=vmax,
+ transform=ccrs.PlateCarree(),
+ add_colorbar=False,
+ cmap="viridis",
+ )
+
+ cbar = plt.colorbar(
+ im,
+ ax=ax,
+ orientation="vertical",
+ pad=0.03,
+ aspect=20,
+ shrink=0.6,
+ fraction=0.04,
+ anchor=(0.0, 0.5),
+ )
+ cbar.set_label(
+ v.name if hasattr(v, "name") else "Value", fontsize=9, labelpad=2
+ )
+ cbar.ax.tick_params(labelsize=7)
+
+ # ax.coastlines()
+ ax.set_title(title, fontsize=12)
+ gl = ax.gridlines(draw_labels=True, linewidth=0.5)
+ gl.top_labels = False
+ gl.right_labels = False
+
+ for i, v in enumerate(vars):
+ if len(vars) == 1:
+ plot(ax, v, titles[i])
+ else:
+ plot(ax[i], v, titles[i])
+
+ plt.savefig(
+ save_name, bbox_inches="tight", pad_inches=0.1, transparent="true", dpi=200
+ )
+ plt.close()
+
+
+def test_visualize(step, data_dir, save_dir):
+ src_name = os.path.join(data_dir, f"{step:03d}.nc")
+ ds = xr.open_dataarray(src_name).isel(time=0)
+ ds = ds.sel(lon=slice(0, 360), lat=slice(90, -90))
+ print(ds)
+ u850 = ds.sel(level="U850", step=step)
+ v850 = ds.sel(level="V850", step=step)
+ ws850 = np.sqrt(u850**2 + v850**2)
+ visualize(
+ f"{save_dir}/{step:03d}.jpg",
+ [ws850],
+ [f"Weather forecasting in 20230725-18+{step:03d}h"],
+ vmin=0,
+ vmax=30,
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--data_dir", type=str, required=True, help="The input data dir"
+ )
+ parser.add_argument("--save_dir", type=str, default="output_fuxi")
+ parser.add_argument("--step", type=int, required=True, help="the predict step")
+ args = parser.parse_args()
+
+ test_visualize(args.step, args.data_dir, args.save_dir)
From 99af63e0f7c76f81f6eeecabfe32270ccfbd7651 Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Fri, 9 May 2025 00:08:30 +0800
Subject: [PATCH 4/7] feat(ppsci): support fuxi for inference
---
README.md | 2 +-
docs/zh/examples/fuxi.md | 16 +++++++++----
examples/fuxi/util.py | 49 --------------------------------------
examples/fuxi/visualize.py | 2 +-
4 files changed, 13 insertions(+), 56 deletions(-)
diff --git a/README.md b/README.md
index 3db545c09..858a0b196 100644
--- a/README.md
+++ b/README.md
@@ -118,7 +118,7 @@ PaddleScience 是一个基于深度学习框架 PaddlePaddle 开发的科学计
| 天气预报 | [NowCastNet 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/nowcastnet) | 数据驱动 | GAN | 监督学习 | [MRMS](https://app.globus.org/file-manager?origin_id=945b3c9e-0f8c-11ed-8daf-9f359c660fbd&origin_path=%2F~%2Fdata%2F) | [Paper](https://www.nature.com/articles/s41586-023-06184-4) |
| 天气预报 | [GraphCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/graphcast) | 数据驱动 | GNN | 监督学习 | - | [Paper](https://arxiv.org/abs/2212.12794) |
| 天气预报 | [GenCast 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/gencast) | 数据驱动 | Diffusion+Graph transformer | 监督学习 | [Gencast](https://console.cloud.google.com/storage/browser/dm_graphcast) | [Paper](https://arxiv.org/abs/2312.15796) |
-| 天气预报 | [Fuxi 气象预报](./zh/examples/fuxi.md) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2306.12873) |
+| 天气预报 | [Fuxi 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fuxi) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/abs/2306.12873) |
| 天气预报 | [FengWu 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/fengwu) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2304.02948) |
| 天气预报 | [Pangu-Weather 气象预报](https://paddlescience-docs.readthedocs.io/zh-cn/latest/zh/examples/pangu_weather) | 数据驱动 | Transformer | 监督学习 | - | [Paper](https://arxiv.org/pdf/2211.02556) |
| 大气污染物 | [UNet 污染物扩散](https://aistudio.baidu.com/projectdetail/5663515?channel=0&channelType=0&sUid=438690&shared=1&ts=1698221963752) | 数据驱动 | UNet | 监督学习 | [Data](https://aistudio.baidu.com/datasetdetail/198102) | - |
diff --git a/docs/zh/examples/fuxi.md b/docs/zh/examples/fuxi.md
index fd994b26a..db7794a13 100644
--- a/docs/zh/examples/fuxi.md
+++ b/docs/zh/examples/fuxi.md
@@ -48,12 +48,12 @@ FuXi模型开发的关键方面和背景包括:
模型结构
-FuXi模型使用了第五代ECMWF再分析数据集ERA5。该数据集提供了从1940年1月至今的地表和高空参数的逐小时数据。ERA5数据集是通过同化使用ECMWF的集成预报系统(IFS)模型获得的高质量和丰富的全球观测资料而生成的。 ERA5数据被广泛认为是全面而准确的再分析档案,这使其适合作为训练FuXi模型的地面实况。对于FuXi模型,使用了ERA5数据集的一个子集,该子集跨越39年,具有0.25°的空间分辨率和6小时的时间分辨率。 该模型旨在预测13个压力层的5个高空大气变量和5个地表变量。
+FuXi模型使用了第五代ECMWF再分析数据集ERA5。该数据集提供了从1940年1月至今的地表和高空参数的逐小时数据。ERA5数据集是通过同化使用ECMWF的集成预报系统(IFS)模型获得的高质量和丰富的全球观测资料而生成的。ERA5数据被广泛认为是全面而准确的再分析档案,这使其适合作为训练FuXi模型的地面实况。对于FuXi模型,使用了ERA5数据集的一个子集,该子集跨越39年,具有0.25°的空间分辨率和6小时的时间分辨率。该模型旨在预测13个压力层的5个高空大气变量和5个地表变量。
数据集被分为训练集、验证集和测试集。训练集包含1979年至2015年的54020个样本,验证集包含2016年和2017年的2920个样本,样本外测试集包含2018年的1460个样本。此外,还创建了两个参考数据集HRES-fc0和ENS-fc0,以评估ECMWF高分辨率预报(HRES)和集合平均(EM)的性能。
## 2. 模型原理
-FuXi模型是一种自回归模型,它利用前两个时间步的天气参数(Xt-1, Xt)作为输入,来预测下一个时间步的天气参数(Xt+1)。其中,t、t-1和t+1分别代表当前、前一个和下一个时间步。本模型中使用的时间步长为6小时。通过将模型的输出用作后续预测的输入,该系统可以生成不同预报时效的预报。
+FuXi模型是一种自回归模型,它利用前两个时间步的天气参数($X^{t-1}$, $X^t$)作为输入,来预测下一个时间步的天气参数($X^{t+1}$)。其中,t、t-1和t+1分别代表当前、前一个和下一个时间步。本模型中使用的时间步长为6小时。通过将模型的输出用作后续预测的输入,该系统可以生成不同预报时效的预报。
使用单个FuXi模型生成15天预报需要进行60次迭代。与基于物理的NWP模型不同,纯数据驱动的ML模型缺乏物理约束,这可能导致长期预报的误差显著增长和不切实际的预测结果。使用自回归多步损失可以有效减少长期预报的累积误差。这种损失函数类似于四维变分数据同化(4D-Var)方法中使用的成本函数,其目的是识别在同化时间窗内与观测结果最佳拟合的初始天气条件。虽然增加自回归步数可以提高长期预报的准确性,但也会降低短期预报的准确性。此外,与增加4D-Var的同化时间窗类似,增加自回归步数需要更多的内存和计算资源来处理训练过程中的梯度。
@@ -63,6 +63,12 @@ FuXi模型是一种自回归模型,它利用前两个时间步的天气参数(
首先,高维输入数据通过联合时空Cube Embedding被降维到C×180×360,其中C是通道数,设置为1536。Cube Embedding的主要目的是减少输入数据的时间和空间维度,降低数据冗余度。随后,U-Transformer处理嵌入后的数据,并使用一个简单的FC层进行预测。输出结果首先被reshape为70×720×1440,然后通过双线性插值恢复到原始输入形状70×721×1440。
+U-Transformer由48个重复的Swin Transformer V2块构建,并按如下方式计算缩放余弦注意力:
+
+$$Attention(Q, K, V) = (cos(Q, K)/\tau +B)V$$
+
+其中B表示相对位置偏差,是一个可学习的标量,在不同的head和层之间不共享。余弦函数是自然归一化的,这导致较小的注意力值。
+
模型使用预训练权重推理,接下来将介绍模型的推理过程。
## 3. 模型构建
@@ -79,7 +85,7 @@ FuXi采用级联模型结构,通过`fuxi_short.yaml`、`fuxi_medium.yaml`、`f
## 4. 结果可视化
-使用 `examples/fuxi/predict.py` 进行画图,进行结果可视化。
+使用 `examples/fuxi/visualize.py` 进行画图,进行结果可视化。
## 5. 完整代码
@@ -93,10 +99,10 @@ examples/fuxi/predict.py
模型推理结果包含 60 个 NetCDF 文件,表示从预测时间点开始,未来 15 天内每个模型20个时间步的气象数据。
-使用 `examples/fuxi/predict.py` 进行画图,进行结果可视化。
+使用 `examples/fuxi/visualize.py` 进行画图,进行结果可视化。
```python
-python3.10 visualize.py --data_dir outputs_fuxi_pd/ --save_dir outputs_fuxi_pd/ --step 6
+python3 visualize.py --data_dir outputs_fuxi/ --save_dir outputs_fuxi/ --step 6
```
下图展示了
diff --git a/examples/fuxi/util.py b/examples/fuxi/util.py
index 14008dabe..4010d0bc7 100644
--- a/examples/fuxi/util.py
+++ b/examples/fuxi/util.py
@@ -71,55 +71,6 @@ def rename(name):
ds.to_netcdf(save_name)
-def visualize(save_name, vars=[], titles=[], vmin=None, vmax=None):
- import cartopy.crs as ccrs
- import matplotlib.pyplot as plt
-
- fig, ax = plt.subplots(
- len(vars), 1, figsize=(8, 6), subplot_kw={"projection": ccrs.PlateCarree()}
- )
-
- def plot(ax, v, title):
- v.plot(
- ax=ax,
- x="lon",
- y="lat",
- vmin=vmin,
- vmax=vmax,
- transform=ccrs.PlateCarree(),
- add_colorbar=False,
- )
- # ax.coastlines()
- ax.set_title(title)
- gl = ax.gridlines(draw_labels=True, linewidth=0.5)
- gl.top_labels = False
- gl.right_labels = False
-
- for i, v in enumerate(vars):
- if len(vars) == 1:
- plot(ax, v, titles[i])
- else:
- plot(ax[i], v, titles[i])
-
- plt.savefig(
- save_name, bbox_inches="tight", pad_inches=0.1, transparent="true", dpi=200
- )
- plt.close()
-
-
-def test_visualize(step, data_dir):
- src_name = os.path.join(data_dir, f"{step:03d}.nc")
- ds = xr.open_dataarray(src_name).isel(time=0)
- ds = ds.sel(lon=slice(90, 150), lat=slice(50, 0))
- print(ds)
- u850 = ds.sel(level="U850", step=step)
- v850 = ds.sel(level="V850", step=step)
- ws850 = np.sqrt(u850**2 + v850**2)
- visualize(
- f"ws850/{step:03d}.jpg", [ws850], [f"20230725-18+{step:03d}h"], vmin=0, vmax=30
- )
-
-
def test_rmse(output_name, target_name):
output = xr.open_dataarray(output_name)
output = output.isel(time=0).sel(step=120)
diff --git a/examples/fuxi/visualize.py b/examples/fuxi/visualize.py
index a36f3afc1..ade810b1c 100644
--- a/examples/fuxi/visualize.py
+++ b/examples/fuxi/visualize.py
@@ -75,7 +75,7 @@ def test_visualize(step, data_dir, save_dir):
visualize(
f"{save_dir}/{step:03d}.jpg",
[ws850],
- [f"Weather forecasting in 20230725-18+{step:03d}h"],
+ [f"850 hPa Wind Speed Forecasting (m/s) in 20231012-00+{step:03d}h"],
vmin=0,
vmax=30,
)
From 81f6b00f7abf642fe5209851b555ae1a5baf80ec Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Fri, 9 May 2025 02:27:18 +0000
Subject: [PATCH 5/7] feat(ppsci): support fuxi for inference
---
mkdocs.yml | 1 +
1 file changed, 1 insertion(+)
diff --git a/mkdocs.yml b/mkdocs.yml
index 8146ac3cf..ac598704f 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -107,6 +107,7 @@ nav:
- IOPS: zh/examples/iops.md
- Pang-Weather: zh/examples/pangu_weather.md
- FengWu: zh/examples/fengwu.md
+ - FuXi: zh/examples/fuxi.md
- 化学科学(AI for Chemistry):
- Moflow: zh/examples/moflow.md
- IFM: zh/examples/ifm.md
From 8351144b1e16904ecf78da66c1317d8446b4dfa8 Mon Sep 17 00:00:00 2001
From: xiaoyewww <641311428@qq.com>
Date: Mon, 12 May 2025 00:39:44 +0800
Subject: [PATCH 6/7] feat(ppsci): support fuxi for inference
---
docs/zh/examples/fuxi.md | 4 ++--
examples/fuxi/predict.py | 11 +++++++----
examples/fuxi/visualize.py | 2 +-
3 files changed, 10 insertions(+), 7 deletions(-)
diff --git a/docs/zh/examples/fuxi.md b/docs/zh/examples/fuxi.md
index db7794a13..a09687e23 100644
--- a/docs/zh/examples/fuxi.md
+++ b/docs/zh/examples/fuxi.md
@@ -75,9 +75,9 @@ $$Attention(Q, K, V) = (cos(Q, K)/\tau +B)V$$
在该案例中,实现了 FuXiPredictor用于ONNX模型的推理:
-``` py linenums="74" title="examples/fuxi/predict.py"
+``` py linenums="44" title="examples/fuxi/predict.py"
--8<--
-examples/fuxi/predict.py:44:121
+examples/fuxi/predict.py:44:124
--8<--
```
diff --git a/examples/fuxi/predict.py b/examples/fuxi/predict.py
index 12d6bf43b..dac50ee1b 100644
--- a/examples/fuxi/predict.py
+++ b/examples/fuxi/predict.py
@@ -85,16 +85,19 @@ def __init__(
def predict(
self, input_data, tembs, global_step, stage, num_step, data, batch_size: int = 1
- ):
+ ) -> tuple[np.ndarray, int]:
"""Predicts the output of the yinglong model for the given input.
Args:
- input_data_prev(np.ndarray): Atomospheric data at the first time moment.
- input_data_next(np.ndarray): Atmospheric data six later.
+ input_data(np.ndarray): Atomospheric data of two preceding time steps
+ tembs(np.ndarray): Encoded timestamp.
+ global_step (int): The global step of forecast.
+ stage (int): The stage of forecast model.
+ num_step (int): The Number of forecast steps.
batch_size (int, optional): Batch size, now only support 1. Defaults to 1.
Returns:
- List[np.ndarray]: Prediction for next 56 hours.
+ tuple[np.ndarray, int]: Prediction for one stage and the global step.
"""
if batch_size != 1:
raise ValueError(
diff --git a/examples/fuxi/visualize.py b/examples/fuxi/visualize.py
index ade810b1c..635b18189 100644
--- a/examples/fuxi/visualize.py
+++ b/examples/fuxi/visualize.py
@@ -73,7 +73,7 @@ def test_visualize(step, data_dir, save_dir):
v850 = ds.sel(level="V850", step=step)
ws850 = np.sqrt(u850**2 + v850**2)
visualize(
- f"{save_dir}/{step:03d}.jpg",
+ os.path.join(save_dir, f"{step:03d}.jpg"),
[ws850],
[f"850 hPa Wind Speed Forecasting (m/s) in 20231012-00+{step:03d}h"],
vmin=0,
From 6f6df79854bd7d681b0205ad487ccb3d3be76bb6 Mon Sep 17 00:00:00 2001
From: HydrogenSulfate <490868991@qq.com>
Date: Mon, 12 May 2025 01:02:04 +0800
Subject: [PATCH 7/7] Update examples/fuxi/predict.py
---
examples/fuxi/predict.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/examples/fuxi/predict.py b/examples/fuxi/predict.py
index dac50ee1b..00e527f73 100644
--- a/examples/fuxi/predict.py
+++ b/examples/fuxi/predict.py
@@ -93,7 +93,7 @@ def predict(
tembs(np.ndarray): Encoded timestamp.
global_step (int): The global step of forecast.
stage (int): The stage of forecast model.
- num_step (int): The Number of forecast steps.
+ num_step (int): The number of forecast steps.
batch_size (int, optional): Batch size, now only support 1. Defaults to 1.
Returns: